engineering
DittoBench: Clocking Tool-Calling, Memory, and Speed in Any Agent Harness
A benchmark for any agentic harness that wields tools and memory — not just SWE. DittoBench clocks 10 models on whether they call the right tool, find the right memory, and how fast they do both, with a composite speed score that puts latency on the same footing as quality.
On this page
- The two axes that matter
- Testing against the real tool catalog
- Growing the dataset to match the depth
- How a tool-calling case is scored
- Speed: putting latency on the same footing as quality
- The June 2026 roster
- The leaderboard
- Tool calling (177 cases × 10 models)
- LongMemEval (150 questions × 10 models)
- Composite speed
- Does fusing models help?
- Reproducibility
- Next: DittoBench becomes a Bittensor competition (subnet 118)
- Anti-cheat: a fresh dataset for every submission
- Why this matters
DittoBench: Clocking Tool-Calling, Memory, and Speed in Any Agent Harness
Every harness that gives a model tools and memory — a chat agent, a coding agent, a research agent, a voice assistant — lives or dies on three questions: does it call the right tool, does it surface the right memory, and how fast does it do both? DittoBench measures exactly those three axes. We built it for Ditto, but nothing about the methodology is Ditto-specific: any harness with a tool catalog and a memory store can be scored the same way.
Every time you send Ditto a message, an agent has to make a series of small, consequential decisions. Should I search your memories, or just answer? Is this a “build me an app” request that needs the coding harness, or a “write me a doc” request that needs the artifacts tool? Do I read the URL you pasted, or search the web? Get those calls right and Ditto feels telepathic. Get them wrong and it either ignores what you said or goes off and does the wrong thing.
Public leaderboards don’t measure that. They measure a model in the abstract — on someone else’s tools, someone else’s prompts, someone else’s memory store. DittoBench measures the thing we actually ship: the Ditto agent, with the real Ditto system prompt, the real Ditto tool catalog, and a real seeded memory store, across every model we might put behind it.
This post covers what DittoBench is, how the tool-calling suite presents the real production tool catalog, the 5.5× dataset expansion behind it, and a composite speed score that puts latency on the same footing as quality — with the full June 2026 leaderboard across 10 models.
The two axes that matter
DittoBench scores Ditto along several axes, but two carry most of the weight because they map directly to what users feel:
- Tool calling (Ditto core) — did the agent pick the right tool, with the right arguments, and not over-call? This is the difference between “Ditto just did the thing” and “Ditto wrote me a paragraph when I asked it to build something.”
- Memory retrieval (LongMemEval) — can Ditto find the right memory from a vague question, across a long history? This is the axis behind “Doubling Memory Recall” and “Teaching Memory to Find Itself”. We build on the public LongMemEval dataset (500 labeled long-term-memory questions) but run a harder, end-to-end agentic variant with a modern QA judge — more on that below.
The memory axis was already mature; the tool-calling suite is where we focused most recently — both on what it shows the model and how deeply it probes.
Testing against the real tool catalog
A tool-calling test only means something if the model sees the same set of tools it would see in production — “did the model pick the right tool” is undefined if the right tool wasn’t even on the menu. So the benchmark presents the full post-onboarding catalog the chat agent actually assembles, roughly 28 tools:
- the base memory/web/image tools (
search_memories,search_web,read_links,create_image, …), artifacts— durable documents, web pages, and PDFs the user keeps,execute_agent_jobandexecute_agent_workflow— the Ditto Code coding harness that actually runs code, installs packages, and deploys apps,- a family of natural-language settings tools — “set my theme to dark”, “switch my model to Opus”, “turn on web search”,
edit_image,file_feedback_for_team, and more.
Presenting the whole surface is what makes the single most consequential decision testable: artifacts vs. Ditto Code, document vs. deploy. The harness mocks the tools’ results (a coding job returns a plausible approval envelope, an artifact write returns a new revision, a settings change returns a proposal card) so multi-turn agent loops keep progressing exactly as they would in the app.
Growing the dataset to match the depth
A bigger menu needs a deeper test. The tool-calling dataset went from 32 hand-written cases to 177 — a 5.5× expansion — version-controlled so the benchmark is reproducible and reviewable. (Until now, the fixtures lived only on a laptop; they’re committed now, except the ~15 MB LongMemEval haystack, which stays out of git.)
The new cases aren’t just “more happy paths.” They’re designed around the decision boundaries the real agent actually faces — the places where a capable model still picks wrong:
| Category group | What it probes |
|---|---|
artifacts_vs_code | The load-bearing distinction: a doc/HTML/PDF the user just reads (artifacts) vs. a project that must actually run/build/deploy (execute_agent_job). Half the cases expect each. |
web_vs_links | Discovery (search_web) vs. reading a URL already in the prompt (read_links). |
memory_lookup / memory_subject / memory_followup | General recall (search_memories) vs. entity-graph lookup (search_subjects → search_memories_in_subjects) vs. full-text fetch (fetch_memories). |
settings | ”Make the app dark”, “use Opus”, “bump the font size” → the right set_* proposal tool. |
abstention | Tempting keywords (“remember when…”, “draw on your knowledge”, “build on that”) where the correct move is to answer directly and call no tool. |
arg_precision | Cases that pin a load-bearing argument — e.g. search_memories_in_subjects must include a subject_id. |
In total the set spans 23 categories and exercises 24 distinct tools. Every case is validated against the real catalog at load time: an expected tool name or argument key that doesn’t exist in production is a hard error, not a silent miss.
How a tool-calling case is scored
Each case is one prompt run through the full agent loop. The score has two halves, 0–100:
- Tool accuracy (0–50) — did the agent call the expected tool(s)? Full credit for matching the expected set; a penalty for each unexpected extra call (unless the case explicitly allows extras). A case that expects no tool gets full marks only if the agent stays its hand.
- Judged response quality (0–50) — an LLM judge reads the agent’s final answer against the case’s expected behavior. Calling the right tool but then mangling the result shouldn’t score the same as nailing both.
We also keep the older BFCL-style name-F1 / argument-F1 / trajectory-penalty scores alongside, for continuity with earlier runs.
Speed: putting latency on the same footing as quality
Quality is half the story. A model that picks the perfect tool but takes nine seconds to do it is a worse product than one that’s 95% as good in one second. DittoBench now measures speed on both benchmarks and rolls them into a single composite speed score.
The challenge is that the two axes live on completely different time scales. A tool-calling decision is one short turn. A LongMemEval answer is a multi-hop retrieval-and-reasoning loop. You can’t just average their millisecond numbers — the slow axis would drown out the fast one. So we normalize each suite independently and fleet-relative:
Within each suite, the fastest model scores 100. Every other model is scored
100 × (fastest_p50 / its_p50)— so a model twice as slow as the leader scores 50.
Then the per-model composite speed score is the weighted geometric mean of its available suite indices. We use the geometric mean on purpose: it punishes imbalance. A model that’s lightning-fast at tool calls but a slog on memory shouldn’t be able to hide behind one good number — the geometric mean drags the composite toward the weaker axis.
Here’s the actual dittobench speed output from the June 2026 run (fastest model in each suite = 100):
[speed] by_model (fleet-relative; fastest in each suite = 100)
model composite longmemeval(idx/p50ms) tool_use(idx/p50ms)
openai/gpt-5.4-nano 100.0 100/1976 100/2393
openai/gpt-5.4-mini 71.8 56/3535 92/2595
google/gemini-3.1-flash-lite 69.2 60/3319 80/2977
x-ai/grok-4.3 47.8 41/4829 56/4288
anthropic/claude-opus-4.8 26.3 24/8303 29/8246
anthropic/claude-4.6-sonnet 24.6 19/10336 32/7590
openai/gpt-5.5 23.3 20/9771 27/8894
moonshotai/kimi-k2.7-code 17.2 7/26689 40/5967
google/gemini-3.5-flash 17.2 12/16814 25/9511
google/gemini-3.1-pro-preview 14.9 12/16350 18/13109Read it like this: gpt-5.4-nano is the fastest model in both suites, so it anchors the scale at 100. Kimi K2.7 Code is a useful illustration of why the geometric mean matters — it’s respectably fast on tool calls (index 40) but very slow on the multi-hop memory loop (index 7, a 26.7s p50), so its composite lands at 17.2 rather than being rescued by the tool-calling number. The frontier models (gemini-pro, gpt-5.5, opus, sonnet) cluster at the bottom on speed — they’re thorough, not fast.
Speed metrics fall out of the same runs that measure quality (we record per-answer latency and tokens as we go), so there’s no separate, extra-cost pass. The dittobench speed command merges a tool-calling run and a LongMemEval run into the cross-benchmark leaderboard.
The June 2026 roster
The official DittoBench leaderboard runs the ten most commonly tested models as of June 2026 — spanning the frontier down to the fast, cheap workhorses, so the board shows the whole quality/speed/cost frontier rather than just the top:
| Model | Tier |
|---|---|
openai/gpt-5.5 | Frontier |
google/gemini-3.1-pro-preview | Frontier |
anthropic/claude-opus-4.8 | Frontier |
anthropic/claude-4.6-sonnet | Mid |
google/gemini-3.5-flash | Mid |
moonshotai/kimi-k2.7-code | Mid |
openai/gpt-5.4-mini | Small |
x-ai/grok-4.3 | Mid |
google/gemini-3.1-flash-lite | Small/fast |
openai/gpt-5.4-nano | Small/fast |
The leaderboard
Below is the June 2026 official run: 177 tool-calling cases and 150 LongMemEval questions, each across all 10 models. Tool-calling ran with the full 28-tool production catalog; LongMemEval retrieved through the v2 MLP composite ranker over the full memory history.
Tool calling (177 cases × 10 models)
Composite tool score (0–1): half tool-selection accuracy, half judged response quality.
| Rank | Model | Tool score | name-F1 | p50 latency |
|---|---|---|---|---|
| 1 | Claude 4.6 Sonnet | 0.855 | 0.630 | 7.6s |
| 2 | Claude Opus 4.8 | 0.823 | 0.552 | 8.2s |
| 3 | GPT-5.5 | 0.822 | 0.581 | 8.9s |
| 4 | Gemini 3.1 Pro | 0.821 | 0.619 | 13.1s |
| 5 | Gemini 3.1 Flash-Lite | 0.808 | 0.659 | 3.0s |
| 6 | Grok 4.3 | 0.799 | 0.662 | 4.3s |
| 7 | Gemini 3.5 Flash | 0.790 | 0.520 | 9.5s |
| 8 | Kimi K2.7 Code | 0.787 | 0.601 | 6.0s |
| 9 | GPT-5.4 mini | 0.786 | 0.590 | 2.6s |
| 10 | GPT-5.4 nano | 0.784 | 0.574 | 2.4s |
The headline isn’t the ranking — it’s how flat it is. The small, fast models (Flash-Lite, mini, nano) land within ~0.05 of the frontier on tool selection while being 3–5× faster. Picking the right tool is mostly a “do you understand the catalog” problem, and even the cheap models do.
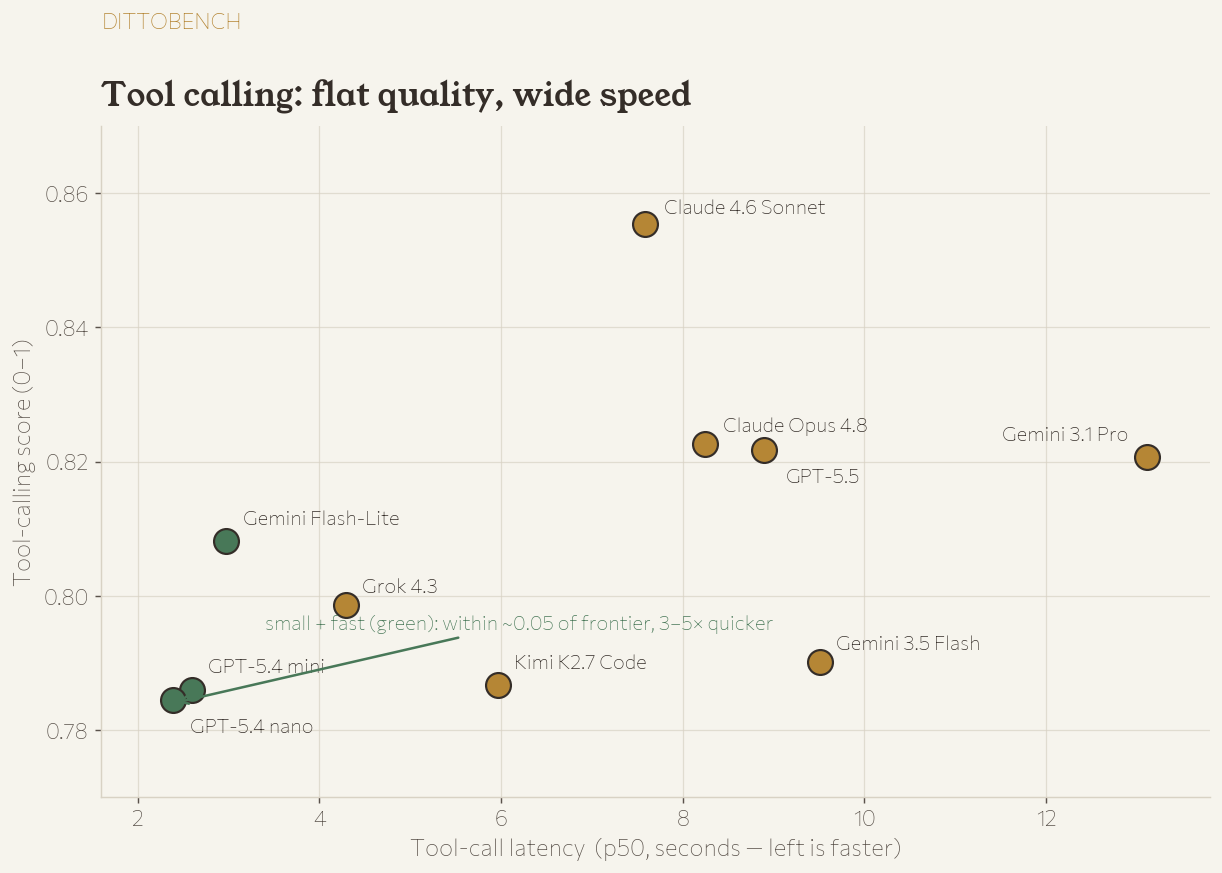
LongMemEval (150 questions × 10 models)
A note on how this differs from the original benchmark. The published LongMemEval (ICLR 2025) hands the model the oracle evidence and grades the answer — it isolates QA from retrieval. Our variant is harder and end-to-end: there is no oracle. The model has to decide to search, query Ditto’s own production v2 retriever over the full memory history, and reason over whatever comes back — so it can fail at retrieval or reasoning, and we score both. On top of that we add a 2026-current LLM-as-judge QA score: a frontier judge model grades each free-form answer against the gold answer with question-type-aware rules (off-by-one tolerance on temporal questions, latest-fact credit on knowledge-update, intent-match on preferences, and explicit credit for correct abstention when the memory genuinely isn’t there). That replaces the brittle string-overlap scoring the original leaned on and reflects how long-context answers are actually evaluated today.
So the two columns below: QA accuracy (did the model answer correctly, end-to-end, judged by a 2026 model) and session recall (did retrieval surface the evidence). Overall accuracy across all models: 0.649 — and that’s the hard setting, not oracle-QA.
| Rank | Model | QA accuracy | session recall |
|---|---|---|---|
| 1 | Kimi K2.7 Code | 0.727 | 0.890 |
| 2 | Gemini 3.5 Flash | 0.720 | 0.908 |
| 3 | Gemini 3.1 Pro | 0.693 | 0.866 |
| 4 | GPT-5.5 | 0.687 | 0.846 |
| 5 | Claude Opus 4.8 | 0.673 | 0.805 |
| 6 | Claude 4.6 Sonnet | 0.653 | 0.886 |
| 7 | Grok 4.3 | 0.633 | 0.795 |
| 8 | GPT-5.4 mini | 0.627 | 0.835 |
| 9 | Gemini 3.1 Flash-Lite | 0.567 | 0.813 |
| 10 | GPT-5.4 nano | 0.507 | 0.781 |
Memory QA separates the field far more than tool-calling did — a 0.22 spread (0.51 → 0.73) vs. ~0.07. Reasoning over a long retrieved context is genuinely harder than picking a tool, and the small models fall away here. Note that session recall stays high and tight (0.78–0.91) across all models because they share the same v2 retriever — recall measures the retriever, QA measures how well each model uses what it surfaced.
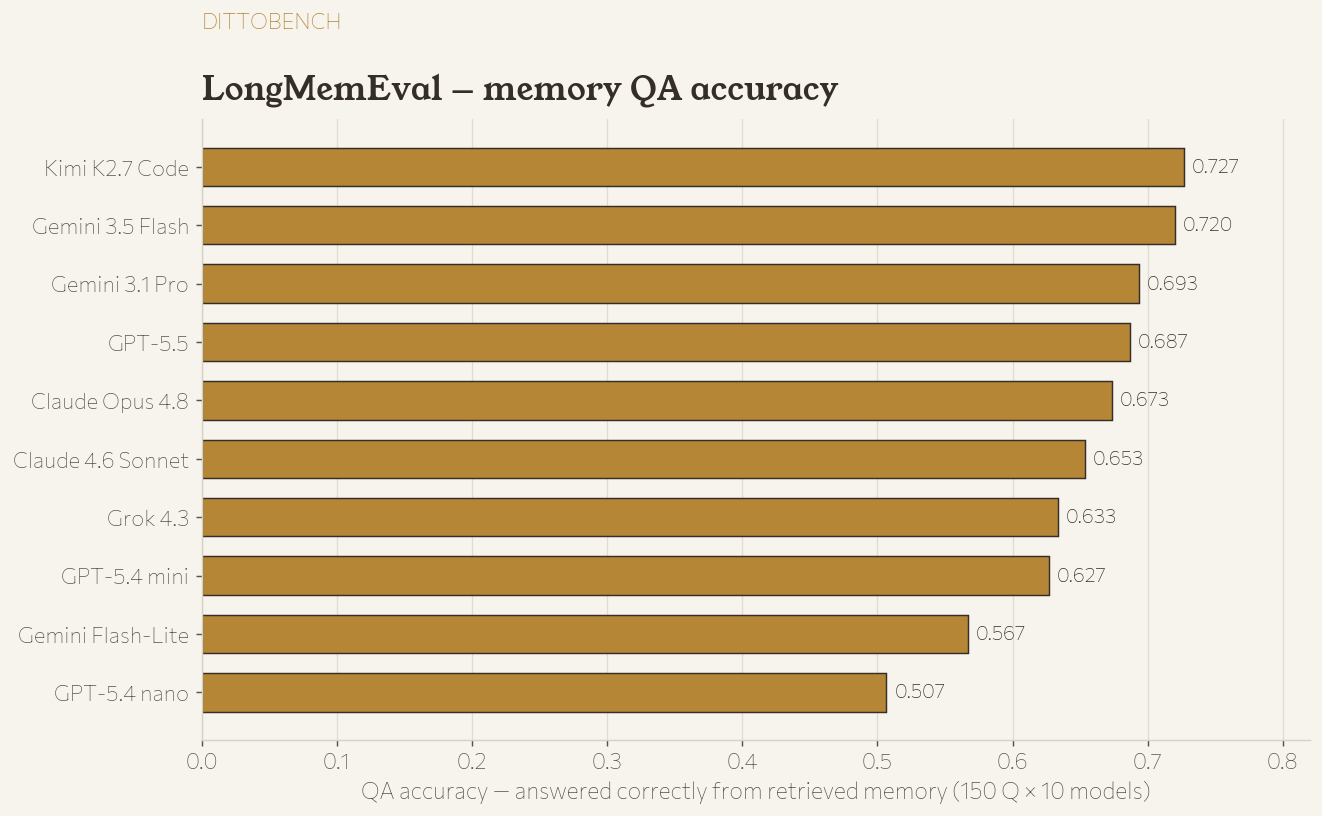
By question type, the difficulty curve matches the published LongMemEval literature:
| Question type | QA accuracy |
|---|---|
| single-session-assistant | 0.932 |
| single-session-user | 0.840 |
| temporal-reasoning | 0.740 |
| knowledge-update | 0.704 |
| single-session-preference | 0.428 |
| multi-session | 0.248 |
Multi-session reasoning — stitching an answer across many separate conversations — remains the hard frontier for every model.
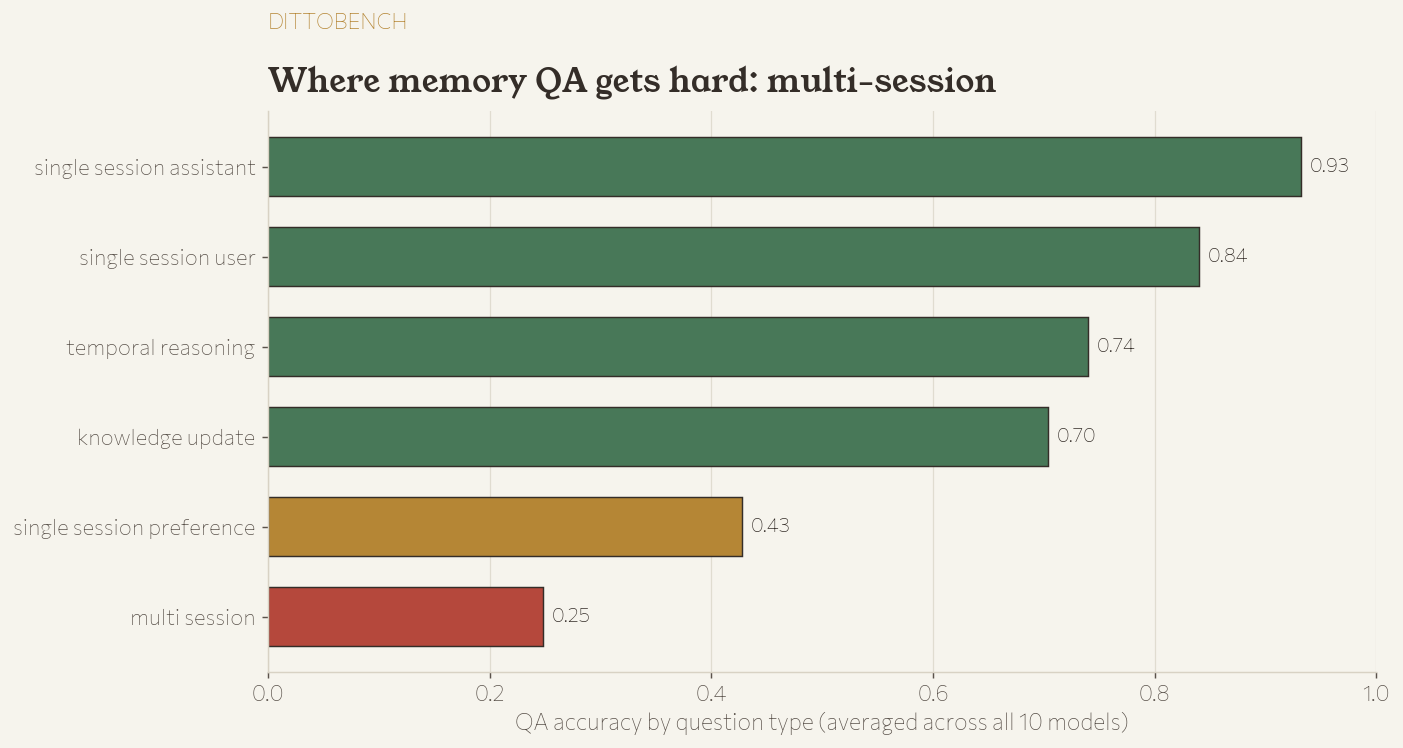
Composite speed
The full dittobench speed board is in the section above. The short version: GPT-5.4 nano is the fastest model on DittoBench (composite 100), with mini (72) and Flash-Lite (69) close behind; the frontier models trail at 15–26 because they reason longer. Cross-referencing with quality is the whole point — Flash-Lite, for instance, is a top-5 tool-caller and the 3rd-fastest model, which makes it a strong default for latency-sensitive tool use even though it’s mid-pack on deep memory QA.
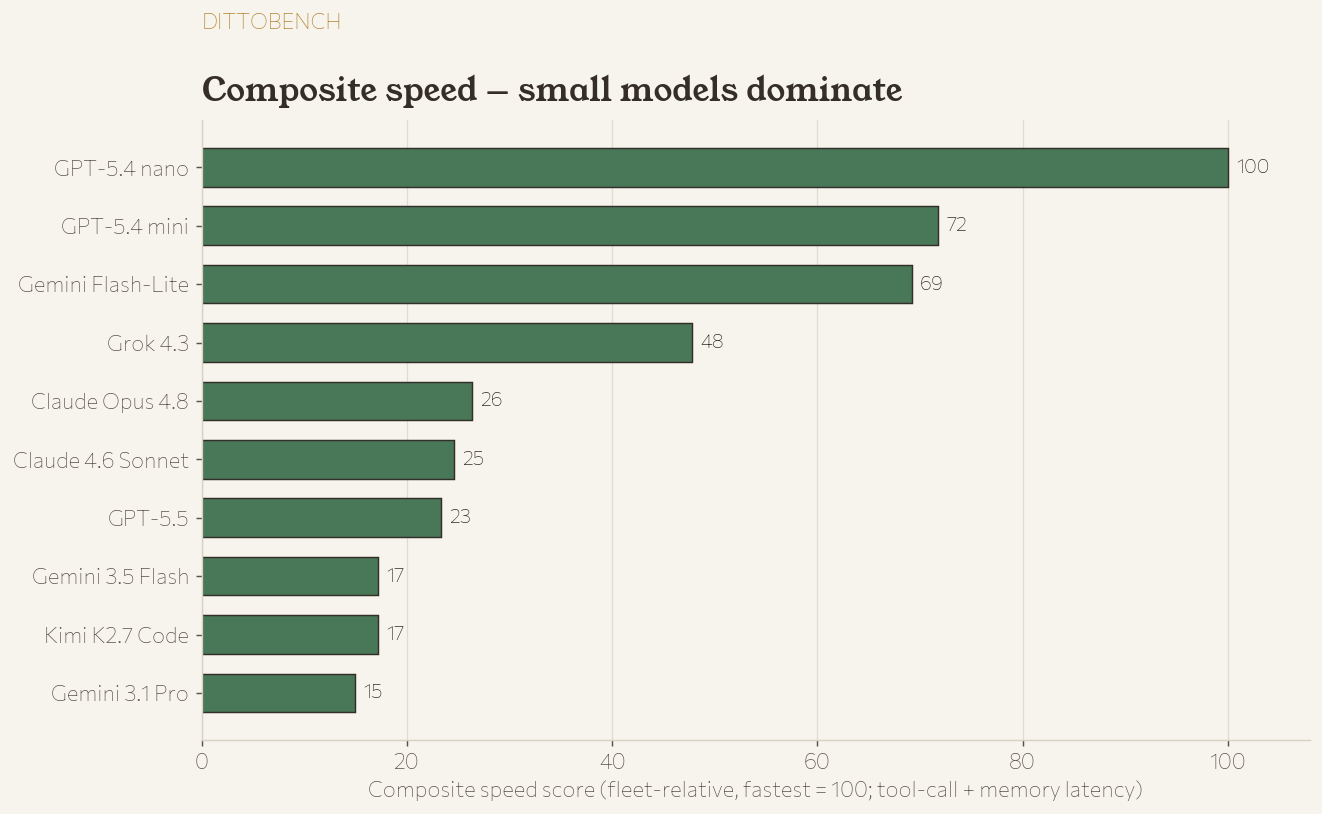
Does fusing models help?
Ditto’s harness can route a turn through OpenRouter Fusion — a panel of models fused into one inference — so we benchmarked three panels on both axes (the same 177 tool cases + 150 memory questions):
| Fusion panel | Tool score | Memory QA |
|---|---|---|
| GPT-5.4 nano + mini + Gemini Flash-Lite | 0.809 | 0.660 |
| Gemini 3.5 Flash + Kimi K2.7 Code | 0.801 | 0.669 |
| Claude Opus 4.8 + GPT-5.5 | 0.772 | 0.676 |
Now the part that genuinely surprised us. Three of the cheapest models on the board — GPT-5.4 nano, GPT-5.4 mini, and Gemini Flash-Lite — fused into a single panel score 0.809 on tool-calling. That’s not just “good for small models.” It out-calls Grok 4.3 (0.799), Gemini 3.5 Flash (0.790), and Kimi K2.7 Code (0.787) running solo — and it beats the fused panel of Opus 4.8 + GPT-5.5 (0.772), the two most expensive models in the lineup. On memory it’s the same shape: the small trio’s 0.660 edges past Claude 4.6 Sonnet (0.653) and Grok 4.3 (0.633) solo. A few cents’ worth of small models, pooled, lands squarely in frontier territory — at roughly an order of magnitude less cost per token.
So does fusion help? It depends entirely on what you’re optimizing for:
- Yes — if you want small models to perform like large ones. This is the headline. Fusion is a cheat code for punching above your weight class: a committee of tiny models reaches scores that otherwise only the frontier touches. If your constraint is cost or latency, you can fuse your way into the big leagues.
- No — if you want the single highest DittoBench score, at least with the three panels we’ve tested so far. None of these beat the best solo model on either axis (Claude 4.6 Sonnet 0.855 on tools, Kimi K2.7 Code 0.727 on memory), and fusing two frontier models was actively counterproductive on tool-calling — Opus and GPT-5.5 each score ~0.82 solo but drop to 0.772 fused, because a crisp “which single tool do I call” decision doesn’t want a committee second-guessing it. But three hand-picked pairings barely scratch the space.
That last point is the open question, not the conclusion. We’ve sampled three panels out of an enormous combinatorial space of models, panel sizes, and routing strategies — and the small-model result already shows fusion can move the frontier. Finding a fusion combo that actually tops the best single model is exactly the search we’ll run next: more models, more groupings, bigger panels, smarter routing. It’s also a natural target for subnet-118 miners — “discover the fusion panel that beats every solo model” is the kind of moving-target problem the competition is built to crowdsource. For now: fuse small to save money, pick one big model to win — until someone finds the panel that does both.
We benchmark fusion precisely so that trade-off is a measured number, not a vibe — and so the next combination we try has a baseline to beat.
Reproducibility
DittoBench is meant to be re-run on every prompt or tool change, so drift shows up before users feel it. The whole official sweep is three commands (wrapped in one script):
# 1. Tool-calling + speed (177 cases × 10 models).
go run ./cmd/dittobench core -suite tools -out dittobench-runs
# 2. LongMemEval QA (150 stratified questions × 10 models).
go run ./cmd/dittobench longmemeval -sample 150 \
-manifest <seed_manifest.json> -out dittobench-runs
# 3. Merge into the composite speed leaderboard.
go run ./cmd/dittobench speed -runs <core-run>.json,<lme-run>.jsonEvery run records the SHA-256 of the system prompt, the tool schemas, and the retrieval weights, so a baseline diff can tell you not just that a score moved but which input moved with it.
Next: DittoBench becomes a Bittensor competition (subnet 118)
A benchmark you only run yourself is a scoreboard. A benchmark the whole world is paid to beat is a flywheel — so we’re turning DittoBench into the validation mechanism for Bittensor subnet 118.
Quick primer. A Bittensor subnet is an open, incentivized competition with two roles: miners do the work, and validators grade it. Validators score each miner, write those scores on-chain as weights, and Yuma Consensus aggregates the stake-weighted weights into TAO emissions — so the miners doing the best work earn the most, continuously, block by block. On subnet 118, DittoBench is the grader. Miners submit improvements to the Ditto agent harness — better retrieval ranking, smarter tool routing, tighter prompting — and validators score each submission on DittoBench’s tool-calling, memory, and speed axes. The leaderboard you just read becomes the thing a global pool of miners is paid to climb.
We’ll ship a miner starter kit so people can compete from day one: the harness, the scoring code, a public practice split of the dataset, per-axis baselines, and a local runner that reports the exact composite the validators use. Optimize against the practice set, submit, get scored on the real thing.
Anti-cheat: a fresh dataset for every submission
The hard part of any benchmark-as-competition is that miners optimize directly against whatever you measure — hand them a fixed test set and they’ll memorize it. So the graded set is never the practice set. Every submission is scored on a freshly generated evaluation set: tool-calling cases synthesized from the live production tool catalog, and memory questions assembled from a held-out haystack under a rotating, validator-controlled seed. No two evaluations are ever identical, and there is nothing static to overfit — a miner can only climb by genuinely getting better at calling tools and using memory, not better at the test.
That’s backed by protocol- and harness-level defenses:
- Fresh-per-submission datasets kill memorization and answer-caching.
- Commit-reveal weights stop validators from copying each other’s scores instead of doing the work.
- Stake-weighted consensus clips outlier validators, so no single grader can swing the board.
- Earliest-submission tiebreak + copy detection deter a miner from cloning the current leader and resubmitting it.
- Provenance hashes — every run records the prompt/tool/weight SHAs, so a winning submission is auditable.
The end state: DittoBench stops being something we run and becomes something a global pool of miners is paid to push forward — and because the grader is the real Ditto harness, every win on subnet 118 is, by construction, an upgrade to the agent real users touch.
Why this matters
A benchmark you run against someone else’s setup tells you which model is good in general. A benchmark you run against your own agent — its real tool catalog, its real prompt, its real memory store — tells you which model is good at the job you actually ship. Those are different questions, and only the second one decides what goes into production.
That’s the bet behind DittoBench: the three things that decide whether a tool-and-memory harness feels great are whether it picks the right tool, finds the right memory, and does both fast — and all three are measurable, on the same agent your users touch. It works for Ditto’s chat agent today; the same harness scores any agent with a tool catalog and a memory store. The numbers above are the June 2026 snapshot — we re-run them on every prompt, tool, and retriever change, so drift shows up before your users feel it.
Open a thread.
Ditto remembers what matters from every conversation, so your next idea starts where your last one left off.