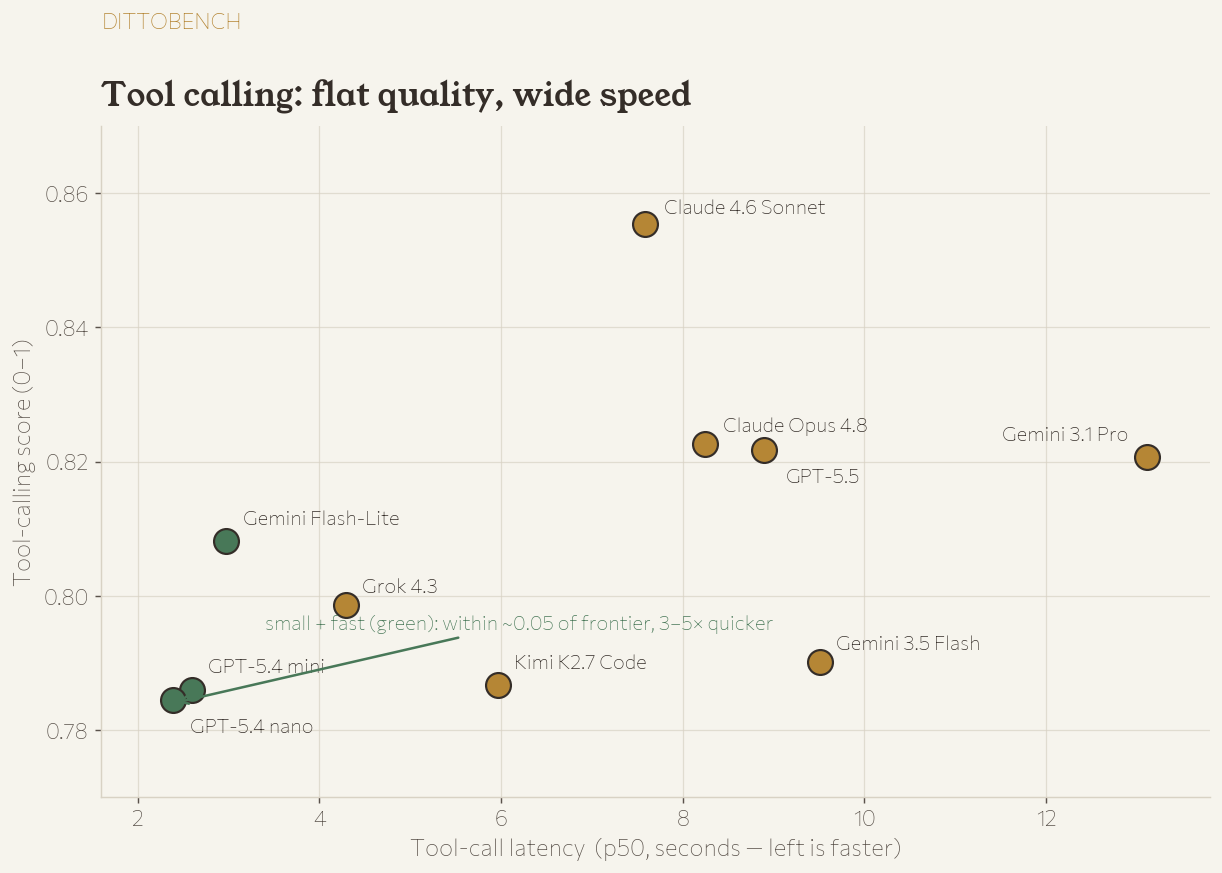
Did it pick the right tool?
- 1 Claude 4.6 Sonnet 0.855
- 2 Claude Opus 4.8 0.823
- 3 GPT-5.5 0.822
- 4 Gemini 3.1 Pro 0.821
- 5 Gemini Flash-Lite 0.808
- 6 Grok 4.3 0.799
- 7 Gemini 3.5 Flash 0.790
- 8 Kimi K2.7 Code 0.787
- 9 GPT-5.4 mini 0.786
- 10 GPT-5.4 nano 0.784
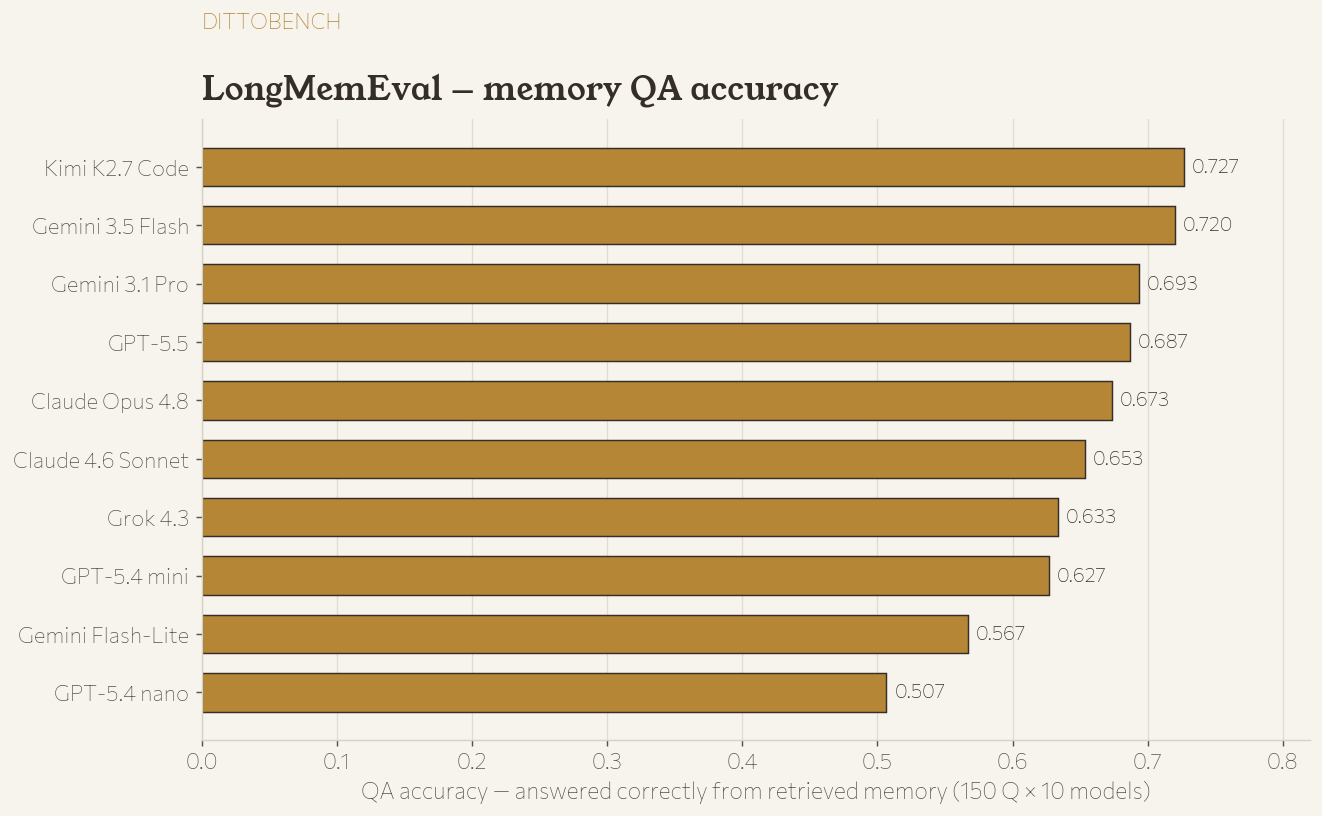
Did it answer from memory?
- 1 Kimi K2.7 Code 0.727
- 2 Gemini 3.5 Flash 0.720
- 3 Gemini 3.1 Pro 0.693
- 4 GPT-5.5 0.687
- 5 Claude Opus 4.8 0.673
- 6 Claude 4.6 Sonnet 0.653
- 7 Grok 4.3 0.633
- 8 GPT-5.4 mini 0.627
- 9 Gemini Flash-Lite 0.567
- 10 GPT-5.4 nano 0.507
The full picture
Every model, every axis.
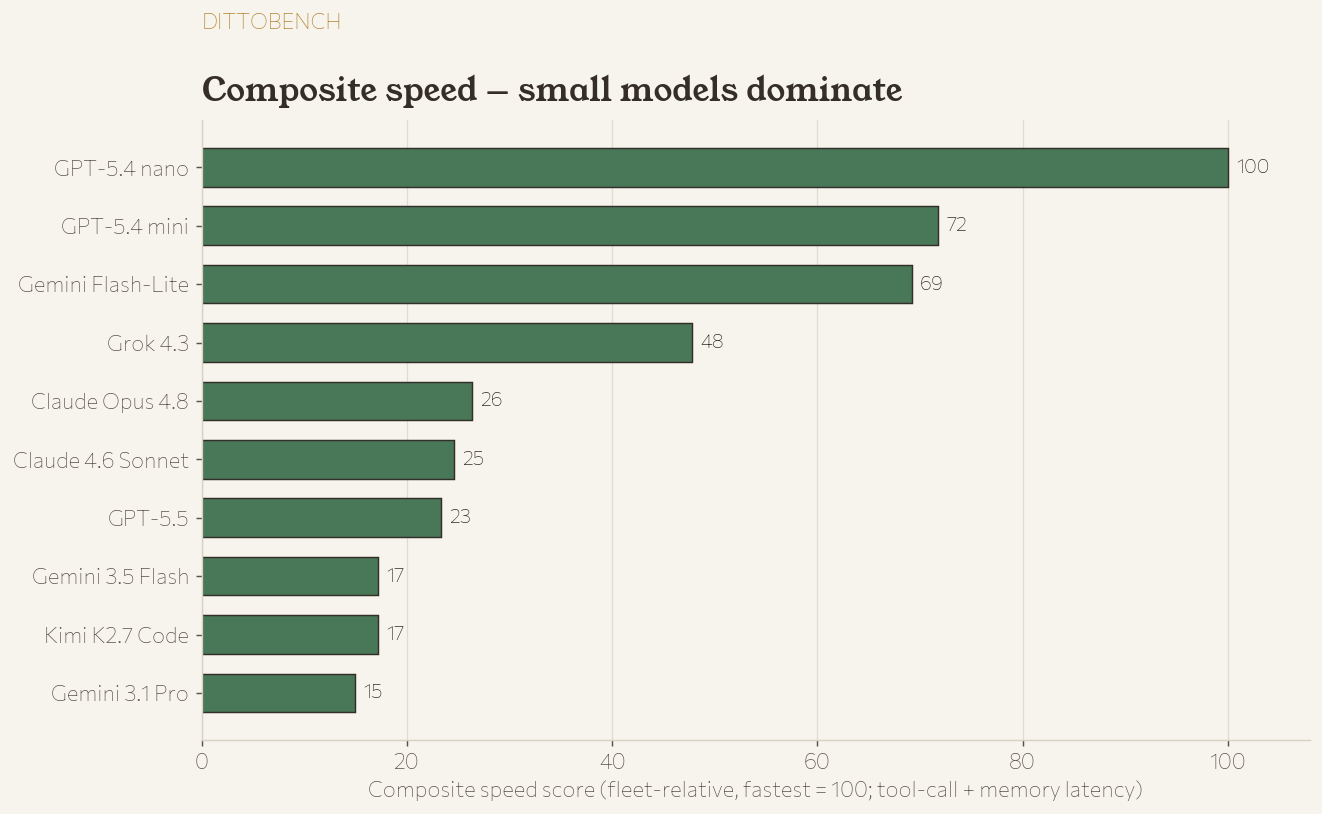
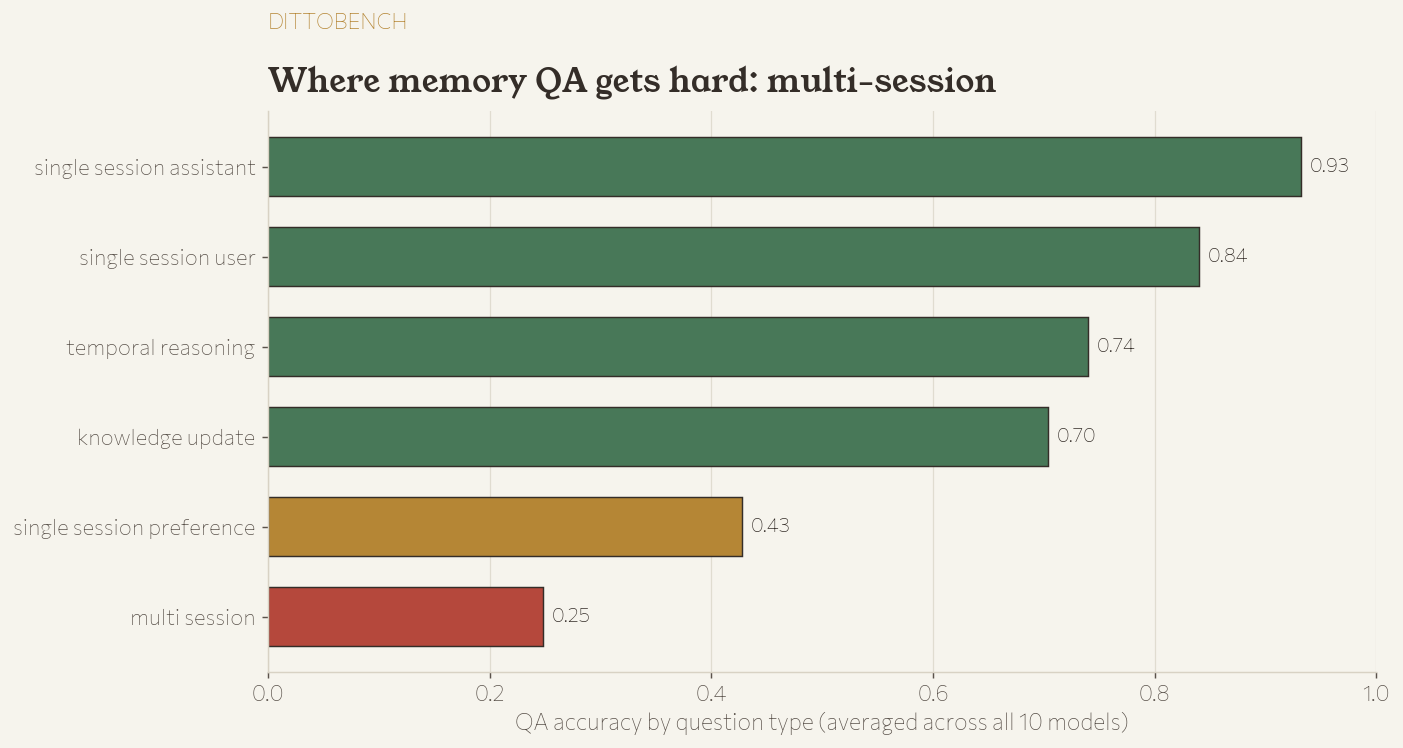
Fusion · OpenRouter
Does fusing models help?
The surprise: three of the cheapest models, nano + mini + Flash-Lite, fused into one panel score 0.809 on tool-calling, out-calling Grok, Gemini 3.5 Flash, and even the fused panel of Opus 4.8 + GPT-5.5. Yes: fusion is how small models punch into frontier territory at a fraction of the cost. No: none of the three panels we've tested yet tops the board, and fusing two frontier models drops below their solo scores. But that's three pairings out of a huge space. Finding a fusion combo that beats every solo model is exactly what we'll explore next (more models, bigger panels). For now: fuse small to save money, pick one big model to win.
- nano + mini + Flash-Lite Tools 0.809 Memory 0.660
- Gemini 3.5 Flash + Kimi K2.7 Tools 0.801 Memory 0.669
- Opus 4.8 + GPT-5.5 Tools 0.772 Memory 0.676
Bars relative to the best single model: tools 0.855 (Claude 4.6 Sonnet) · memory 0.727 (Kimi K2.7 Code). A full bar would mean matching the best solo model.
Want the methodology, the harness internals, and the model-by-model tables? Read the DittoBench writeup →