engineering
Doubling Memory Recall by Extending Ditto's Ranker
We rebuilt the model that decides which past memories Ditto shows the AI. It now considers seven signals instead of three, looks at seventeen hints about your situation instead of six, and was trained directly on the ranking task — roughly doubling how often it surfaces the right memory.
On this page
Doubling Memory Recall by Extending Ditto’s Ranker
In February we shipped a small neural net that picked three numbers — how much to trust topic similarity, how much to trust recency, how much to trust how often a topic comes up — and used those numbers to rank Ditto’s memory of past conversations. That post is here: Learned Retrieval Weights. This is the v2 upgrade.
The new model picks 7 numbers from 17 inputs, the database query that ranks memories now combines four new signals, and we trained the model directly on the ranking task instead of teaching it to imitate an LLM’s guess at good weights. On the LongMemEval benchmark, the model now finds about twice as many of the correct memories in the top 10 results, and ranks them roughly 3x better by every standard retrieval score.
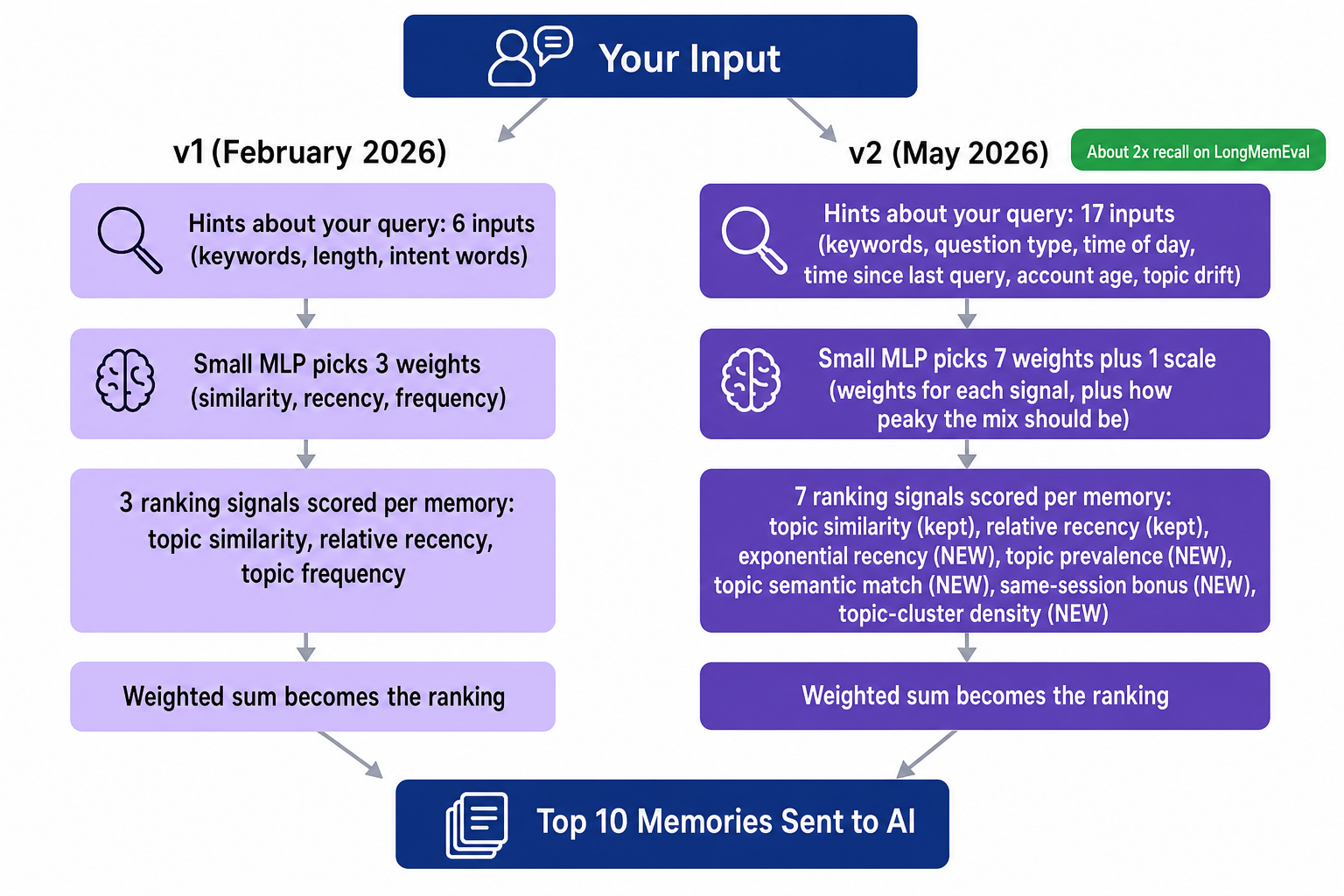
The whole upgrade in one picture — same overall shape, every stage got wider:
A quick refresher on what “ranking memories” means
When you send Ditto a message, Ditto pulls roughly 50 plausible past memories out of the database and has to decide which 10 to actually feed to the AI. Picking the wrong 10 means the AI either misses something important or gets distracted by noise. The piece of code that makes that pick is the ranker. v1 was a small ranker; v2 is a smarter ranker.
What v1 did
v1 took 50 candidate memories and scored each one on three things:
- Cosine similarity — how topically close the memory is to your question (standard vector similarity).
- Linear recency — how recent the memory is, on a 0-to-1 scale within the candidate pool.
- Subject-link frequency — how many other memories share topics with this one (a proxy for “you talk about this a lot”).
A small neural network looked at your query and decided how much to weight each of those three signals — for “what did we talk about yesterday?” it would lean on recency; for “tell me about my Python projects” it would lean on similarity. That worked. The model picked the right dominant signal 98.8% of the time. But it only had three knobs. If the right memory wasn’t near the top of any of those three orderings, no combination of weights could rescue it. Full math is in the v1 post.
The new ranking signals
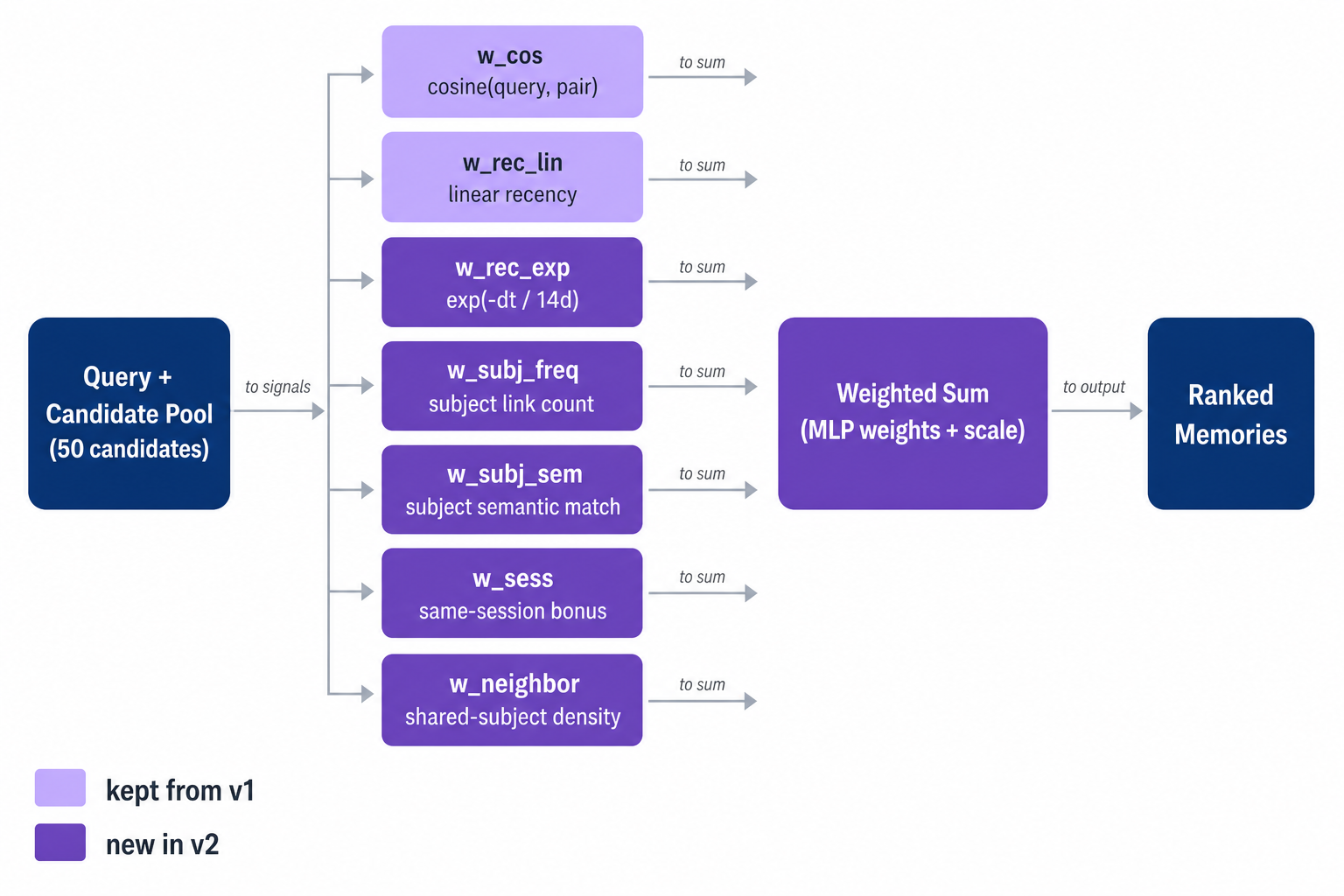
The v2 database query computes seven scores per candidate and combines them with weights from the model. Each score answers a different question about whether a candidate memory is the right one to surface.
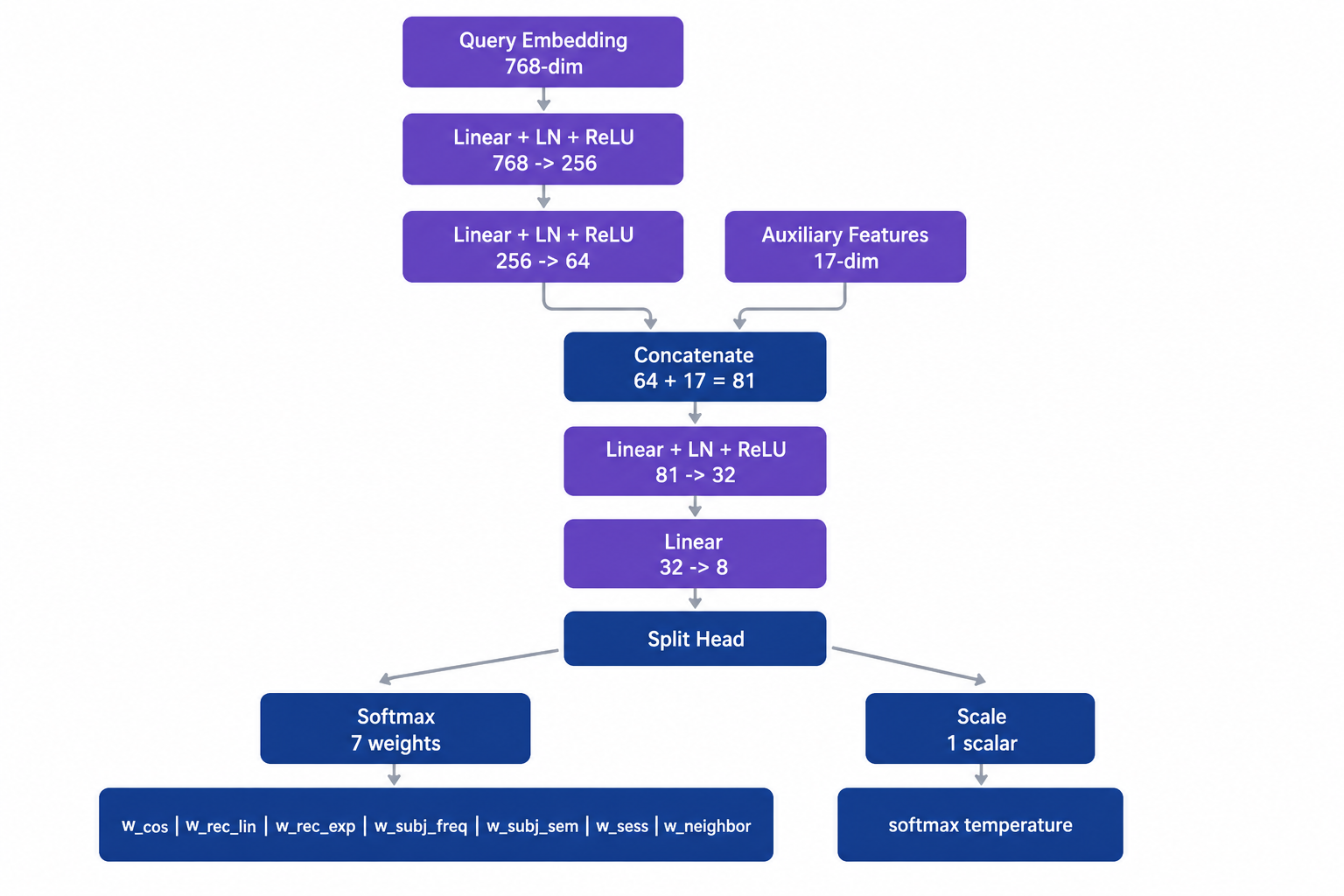
w_cos— topical similarity. Same as v1: how close the memory’s meaning is to your question. Kept from v1.w_rec_lin— relative recency. Same as v1: how recent the memory is compared to the rest of the candidate pool. Kept from v1.w_rec_exp— absolute recency. A second recency score that decays exponentially with a roughly two-week half-life. Why we added it: relative recency loses meaning when the candidate pool spans years; an exponential decay says “anything older than two weeks is roughly equally old”, which matches how people actually treat time. New.w_subj_freq— topic prevalence. How often the memory’s topics appear in the rest of your conversations, normalized so the highest-scoring candidate in the pool is 1.0. Why we split this out: in v1, “frequency” mixed two different ideas — how often a topic appears, and how related the topics are to your question. Separating them lets the model weight each independently.w_subj_sem— topic-level semantic match. For each topic attached to a memory, we measure how close that topic is to your question, and take the best one. Why we added it: a long memory may contain one important phrase buried inside a lot of unrelated text. The memory’s overall similarity score will be diluted, but the topic-level score will still spike. This was the single biggest contributor to the recall jump. New.w_sess— same-session bonus. A small boost for memories that came from the same chat session you’re in right now. Why we added it: when you ask a follow-up question, the most relevant memory is almost always something you said five minutes ago in the same conversation, even if it’s not the most semantically similar match in your entire history. New.w_neighbor_density— topic clustering. How many other candidates in the pool share topics with this one. Why we added it: if eight of the top fifty candidates all share a topic, that topic is probably what your question is really about, and a memory in that cluster is more likely to be what you want. New.
The model also predicts an eighth number we call scale, which controls how peaky or spread-out the weights are. For “what did we talk about yesterday?” scale goes high — almost all the weight piles onto recency. For a vague question, scale goes low — the model spreads weight across multiple signals because it’s not sure which one matters most.
All seven scores and the final ranking are computed inside a single database query. No second pass, no extra service, no extra round-trip.
The new model inputs
In addition to the query itself, the model now sees 17 small extra hints about the situation it’s in. v1 had 6 of these; v2 keeps those and adds 11 more. Each one is cheap to compute and gives the model a clue about which signals to trust:
- Question type (one of: single-session, multi-session, knowledge-update, temporal, preference). Why: a temporal-reasoning question and a knowledge-update question want very different rankings — temporal wants recency, knowledge-update wants the latest version of a fact. Telling the model the question type up front lets it pick the right strategy.
- Time of day (encoded as sine/cosine so midnight and 1 AM are close together, not far apart). Why: daily routines repeat. A “what should I do today?” at 8 AM probably wants different memories than the same question at 10 PM.
- Time since your last query. Why: if you sent a message ten seconds ago, it’s almost certainly a follow-up; if it’s been three days, it’s a fresh context. The model uses this to decide how strongly to weight
w_sessand recency. - Total number of memories you have. Why: a brand-new user with 30 memories needs a different mix than a power user with 30,000. Frequency signals get noisy at small sizes; topic-clustering signals get more useful at large sizes.
- Days since you signed up. Why: correlates with how trustworthy the recency signal is. Old accounts have years of history where “recent” means something different than for a one-week-old account.
- Drift between your question and your average topic. Why: if your question is far from the kind of thing you usually talk to Ditto about, plain similarity is more likely to be the only useful signal — there’s no relevant history to lean on.
The model’s output grew from 3 numbers to 8 (7 signal weights + the scale knob). The shipping binary can load either a v1 or v2 model file by looking at the file’s shape at startup, so the rollout is just dropping a new file in place.
How we trained it: from imitation to direct optimization
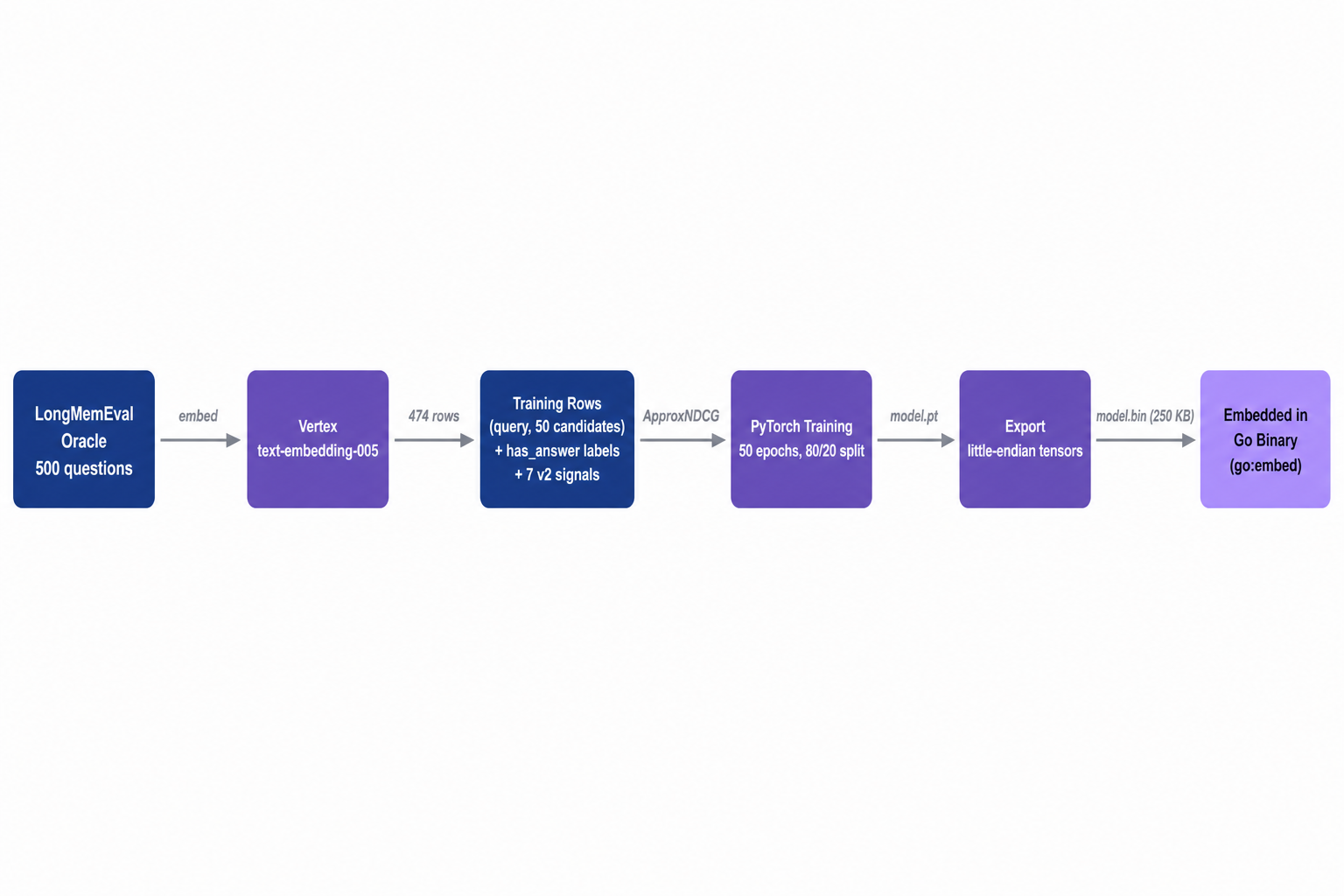
v1 was trained on what’s called distillation. We asked an LLM to look at 1,000 synthetic queries and guess the right weights for each one, then trained the model to match those guesses. That’s a workable shortcut, but the LLM’s guesses are not actually the right answer — they’re a guess at the right answer.
v2 trains on the real task. We took a public benchmark called LongMemEval, which comes with 500 questions and a labeled list of which conversation turns contain the answer to each one. For each question, we pulled a pool of 50 candidate memories, computed the 7 v2 signals for each candidate, and trained the model to push the labeled-correct candidates to the top of its ranking.
The training objective is called ApproxNDCG. Plain English: NDCG is the standard score for “did you put the right things at the top of a ranked list” (more on it below). Standard NDCG isn’t directly trainable because tiny weight changes don’t move discrete ranking positions. ApproxNDCG is a smoothed version that is trainable, and optimizing it has the same effect.
We trained for 50 epochs on an 80/20 train/validation split. Best validation NDCG@10 was 0.8222, vs 0.8134 for a “just use cosine similarity” baseline on the same pools. The mean signal weights the model learned to pick, averaged across the validation set:
| Signal | Mean weight |
|---|---|
| cosine | 0.515 |
| subj_sem | 0.335 |
| subj_freq | 0.086 |
| neighbor_density | 0.025 |
| recency_lin | 0.022 |
| recency_exp | 0.012 |
| sess | 0.006 |
Roughly: the model puts about half its trust in topical similarity, a third in topic-level semantic match (the new w_subj_sem), and treats the rest as tiebreakers. That’s the right shape for an offline benchmark — there’s no concept of a “current session” in LongMemEval, so the model correctly learned that w_sess isn’t useful here.
Retrieval results
We ran 474 LongMemEval questions through both v1 and v2 with identical query embeddings, identical candidate pools, and identical evaluation depth. The only difference is the ranker.
How to read these scores
The first four are all between 0 and 1, where 1 is “perfect ranking” and 0 is “completely wrong”. Each measures a slightly different thing:
- Recall@10 — did we retrieve the correct memories at all? The fraction of correct answers that appeared anywhere in the top 10 results. If there are 4 correct answers and 3 of them are in your top 10, Recall@10 is 0.75.
- NDCG@10 — did we rank them well? Like Recall@10, but it also rewards putting the correct ones higher up. Hitting position 1 is worth more than hitting position 9.
- MRR — how high was the first correct answer? Reciprocal of the rank of the first correct result. Position 1 gives 1.0, position 2 gives 0.5, position 10 gives 0.1.
- Needle hit % — did we find the single most important piece of evidence? The fraction of cases where the one specific “needle” memory that contains the answer made it into the top results.
- pp is a “percentage point”, the difference between two percentages. 50% to 75% is +25 pp.
Overall
| Metric | v1 | v2 | Δ |
|---|---|---|---|
| NDCG@10 | 0.146 | 0.452 | +0.31 |
| NDCG@5 | 0.095 | 0.410 | +0.32 |
| Recall@10 | 0.290 | 0.605 | +0.31 |
| Recall@5 | 0.152 | 0.493 | +0.34 |
| MRR | 0.128 | 0.448 | +0.32 |
| Needle hit % | 15.8% | 49.8% | +34 pp |
In plain English: v1 found the correct memory inside the top 10 about 29% of the time. v2 finds it 60% of the time. v1 found the single most important memory 16% of the time; v2 finds it 50% of the time.
Recall@10 by question type
| Question type | n | v1 | v2 | Δ |
|---|---|---|---|---|
| knowledge-update | 72 | 0.310 | 0.773 | +0.46 |
| single-session-assistant | 51 | 0.353 | 0.863 | +0.51 |
| single-session-user | 64 | 0.438 | 0.828 | +0.39 |
| multi-session | 125 | 0.227 | 0.486 | +0.26 |
| temporal-reasoning | 132 | 0.269 | 0.483 | +0.21 |
| single-session-preference | 30 | 0.178 | 0.311 | +0.13 |
Every category improved. The biggest jumps are on questions where the answer is anchored to a specific topic (single-session, knowledge-update) — the new topic-level matching signals (w_subj_sem and w_subj_freq) do most of the lifting there. Multi-session and temporal questions improved less, because those depend more on the AI being able to reason across multiple retrieved memories than on whether the right memories were retrieved.
End-to-end QA
The retrieval scores above only measure the ranker. The real test is whether better retrieval actually produces better answers when the AI is in the loop. We ran all 500 LongMemEval questions through the full pipeline — Ditto retrieves memories with v2, Gemini 3.1 Pro Preview answers, Gemini 3 Flash grades the answers — and compared to the same setup from a week prior:
| Metric | v1 baseline | v2 | Δ |
|---|---|---|---|
| Composite | 77.8 | 80.2 | +2.4 |
| QA accuracy | 71.2% | 74.0% | +2.8 pp |
| Session recall | 87.6% | 89.5% | +1.9 pp |
Quick definitions:
- QA accuracy — fraction of questions where the AI’s answer was judged correct.
- Session recall — fraction of questions where the right conversation session ended up in the retrieved context (even if the AI then failed to use it).
- Composite — LongMemEval’s blended score combining accuracy across all categories.
Every category improved. But the QA gain (+2.8 pp) is much smaller than the retrieval-only gain (~3x), and it’s worth saying why: once the AI is involved, most of the remaining wrong answers aren’t because Ditto failed to retrieve the right memory. They’re because the AI failed to reason across memories that Ditto did surface. The clearest example is multi-session questions: session recall is 93.2% (the right session shows up in context almost every time), but answer accuracy is 60.2% (the AI fails to stitch together the multi-session story even when looking at it). The retrieval bottleneck has gotten smaller; the reasoning bottleneck is now the limiting factor.
Latency
A nice property of this design: it’s still effectively free. The whole new ranker is a 250 KB file embedded directly in the Ditto backend binary plus one slightly wider database query. No extra services, no extra network calls, no GPU. The wider v2 query takes the same amount of time as v1 in our benchmark, and the model itself runs in under a millisecond. Full end-to-end timing is unchanged.
Limitations
- Trained on one user’s data. All training data came from the LongMemEval benchmark, which is essentially one synthetic user. We’ve now started logging real (anonymized) retrieval decisions in production, and the next training run will use that broader data.
- The same-session signal is sleeping. LongMemEval has no concept of a “current chat session”, so the model never saw an example where
w_sessmattered and learned to ignore it. In real chats it does matter, and v2 currently under-weights it. The next training run on real data will fix this.
Multi-session and temporal-reasoning questions are the next focus — those gained the least, and the evidence above suggests the next round of work belongs on the reasoning side rather than the retrieval side.
Closing
Same overall shape as v1: one small model, one database query, one binary. The work was widening the inputs from 6 hints to 17, widening the outputs from 3 weights to 8, and replacing “imitate an LLM’s guess” with “optimize the real ranking task”. The result is roughly 3x better retrieval on LongMemEval, +2.8 percentage points of end-to-end answer accuracy, and a clearer picture of where to push next.
— Nick & Omar
Open a thread.
Ditto remembers what matters from every conversation, so your next idea starts where your last one left off.