engineering
An Agent's Nightmares Are the Key to Its Dreams
Nobody fully understands why we dream. One theory is memory consolidation - your brain replaying the day and weaving it into what you already know. We built the algorithmic version of that for Ditto. The bugs we shipped along the way? Those were the nightmares.
On this page
- What happens after you close a conversation
- A graph shaped like your brain's index, not a textbook
- The quiet stages
- The only interesting decision: when to merge
- The nightmares are the point
- Stage 5: linking
- Stage 6: refinement, or why the graph gets sharper with use
- How retrieval uses the graph
- Numbers from production
- What dreaming gives up
- Why we call it dreaming
- Where to dig next
An Agent’s Nightmares Are the Key to Its Dreams
Nobody fully understands why we dream. One theory that keeps gaining ground is memory consolidation - the idea that sleep is when your brain replays the day’s experiences, decides what matters, and weaves it into the web of everything you already know. The hippocampus fires patterns back to the cortex. Loose threads get tied to old ones. By morning, you don’t just have more memories. You have better-connected memories.
There’s a darker side to that process. Neuroscientists theorize that nightmares might serve a purpose too - your brain stress-testing its model of the world, surfacing conflicts and contradictions so they can be resolved before they matter. The bad dream isn’t a malfunction. It’s maintenance.
We didn’t set out to build an artificial hippocampus. But when we started working on long-term memory for Ditto - our AI companion at Omni Aura - we kept arriving at the same problem the brain solves during sleep: how do you take a flood of raw experience and quietly, in the background, turn it into structured knowledge that compounds over time? And what do you do when that knowledge conflicts with itself?
The system we built does exactly that. We call it the dreaming pipeline. It has dreams - subjects that merge cleanly, graphs that compound with every conversation. And it has nightmares - merge conflicts, fragmented nodes, topics that should be one but aren’t. The key insight: the nightmares aren’t bugs. They’re the signal the system uses to get smarter.
What happens after you close a conversation
When you finish talking to Ditto, the conversation doesn’t just sit in a row in a database. About thirty seconds later, a background pass re-reads what you said, asks an LLM to extract the durable topics, embeds them, looks for near-duplicates across everything you’ve ever discussed, and stitches the new memory into a graph of subjects you can search, browse, and query against.
This is the structure that makes our Composite MLP v2 ranker possible. Three of its seven retrieval signals - topic prevalence, topic semantic match, and topic-cluster density - read directly from the graph that dreaming builds. The ranker picks the right memories for a question. The graph is what makes those memories worth picking from in the first place.
Here’s the whole pipeline in one picture, then the parts.

A graph shaped like your brain’s index, not a textbook
Most “knowledge graph” diagrams show subjects connected to other subjects with weighted edges. Looks impressive. But it forces you to decide, at write time, which subjects are “related” and how strongly. Every decision is one more place to be wrong.
Ditto’s graph is bipartite. Two kinds of nodes - subjects and memory pairs - and one kind of edge between them. Two subjects are “related” when they show up together in the same memory. The strength of that relationship is just the count of shared memories. The graph is the data. The relationships emerge.
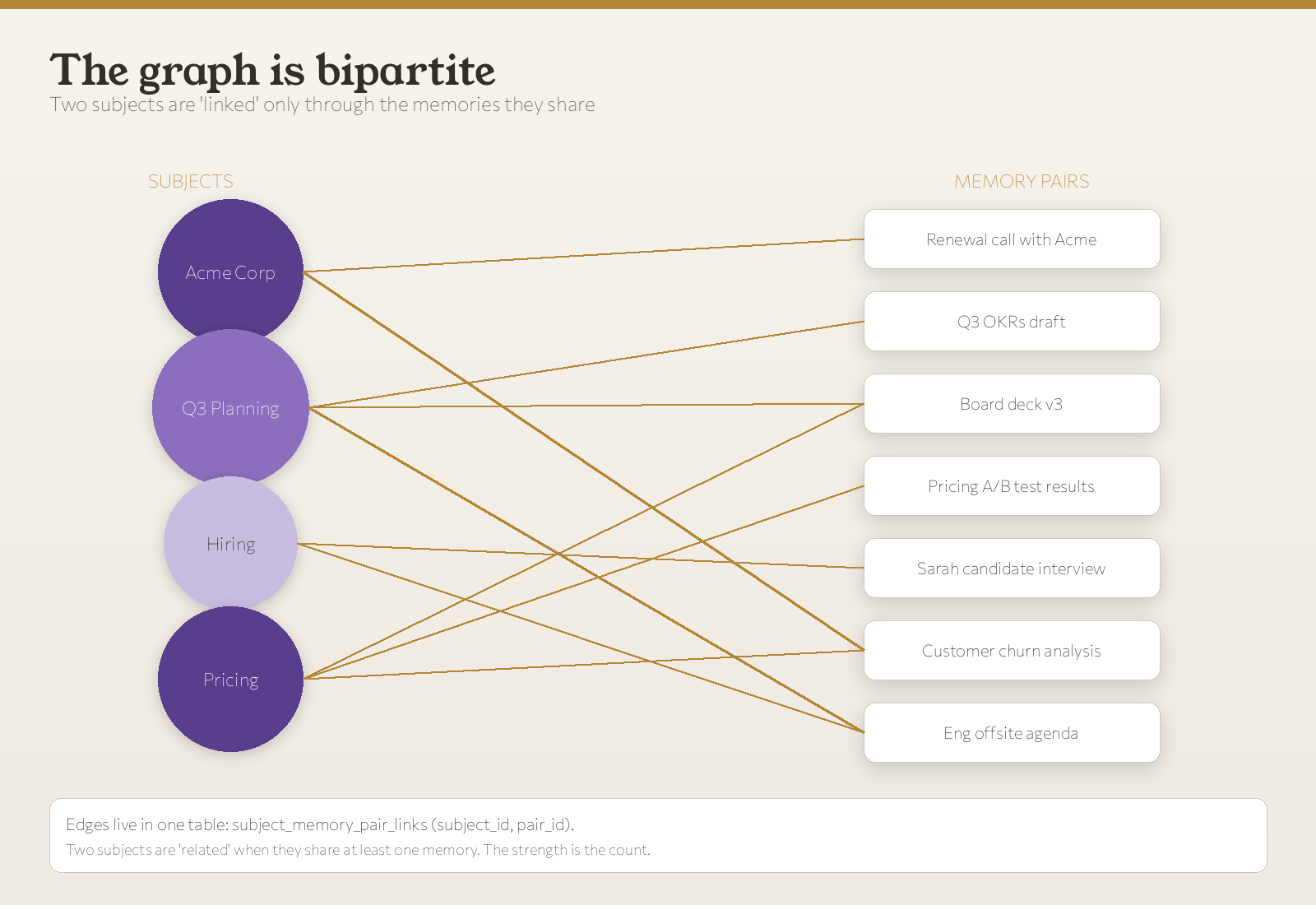
This gives us three things we care about:
- One source of truth. Every “is X related to Y?” question is a single SQL join. No second table to drift out of sync.
- Cheap to update. Adding a new memory means inserting one row per subject. Never updating an existing edge.
- Honest about uncertainty. The graph never claims “Acme Corp and Pricing are 60% related.” It says “you’ve talked about both in eight memories.” You decide what that means.
The entire knowledge graph is one Postgres junction table with a composite primary key:
CREATE TABLE subject_memory_pair_links (
subject_id uuid NOT NULL REFERENCES subjects(id) ON DELETE CASCADE,
pair_id uuid NOT NULL REFERENCES memory_pairs(id) ON DELETE CASCADE,
user_id text NOT NULL,
kg_id text NOT NULL,
created_at timestamptz NOT NULL DEFAULT now(),
PRIMARY KEY (subject_id, pair_id)
);That table is the entire knowledge graph. Everything else is a view on top.
The quiet stages
Stage 1: Persist. Your message becomes a row in the database with a 768-dimensional embedding (Vertex’s text-embedding-005) indexed in pgvector for vector search. Three columns are deliberately left NULL - a summary, extracted topics, and processing timestamps. Those nulls are how the pipeline finds work to do. Each stage queries for rows where the previous stage ran but its own checkpoint is null. The pipeline is, at every point, restartable from the database.
Stage 2: Queue. A batch queue ticks every 30 seconds. If you send five messages in that window, you get one sync job, not five. A per-user lock ensures no concurrent writes to the same graph. There’s a fast path for Ditto’s MCP tool API - sync runs immediately so an agent that just saved a fact can read it back the next turn. Same code, no 30-second wait.
Stage 3: Subject extraction. The only step that calls an LLM during write. We ask a fast model (gpt-5.4-nano, with a gemini-3.1-flash-lite fallback) to return structured JSON: a one-sentence summary and 1–5 durable subjects with names, descriptions, and types.
A few things that took us a while to get right:
- Temperature 0.2, max 800 tokens. Anything higher and the model invents subjects that don’t exist in the text. Anything lower and it gets brittle on long conversations.
- Structured JSON via the
response_formatAPI. A free-form prompt with “return JSON” works 95% of the time. The other 5% is enough to corrupt your graph. - Empty subjects is a valid answer. Not every chitchat exchange deserves a node. If the model says zero subjects, we accept that and mark the pair processed.
The only interesting decision: when to merge
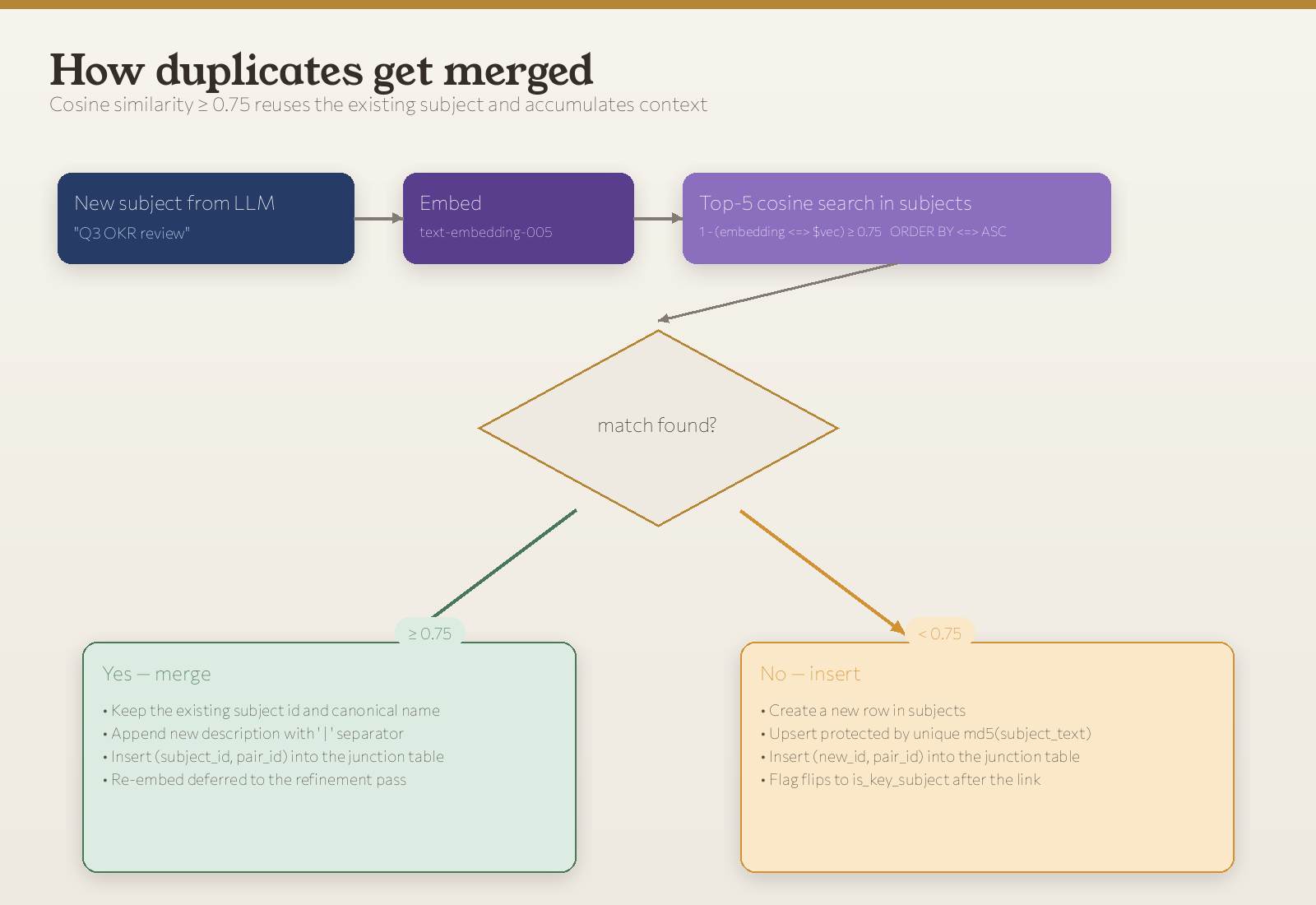
This is where the graph either compounds or fragments. When the LLM says “Q3 OKR review”, do we make a new node, or attach it to the existing “Q3 Planning” node from last month?
Cosine similarity against the user’s existing subject embeddings. Single threshold: 0.75.
SELECT id, subject_text, description_text, subject_type,
1 - (embedding <=> $embedding) AS similarity
FROM subjects
WHERE user_id = $user_id
AND kg_id = $kg_id
AND 1 - (embedding <=> $embedding) >= $similarity_threshold
ORDER BY embedding <=> $embedding ASC
LIMIT 5;The threshold returns the top five candidates ordered by cosine distance. We take the closest match if any survive 0.75, otherwise we insert.
Higher than 0.85 and you fragment: “Q3 OKR review”, “Q3 Planning”, and “Q3 board deck” all become separate nodes when they should be one. Lower than 0.65 and you collapse: “Acme Corp” and “Pricing” merge into one generic blob and the graph stops being useful.
When we merge, two things happen:
- The existing subject ID and canonical name stay. We don’t rename “Q3 Planning” to “Q3 OKR review” just because the latest pair phrased it that way. The first name wins until the refinement pass earns the right to change it.
- The new description gets appended. Postgres stores something like
"Q3 OKR draft with team leads | Q3 board deck revenue targets | Q3 hiring plan headcount". The" | "separator is deliberately ugly so the refinement pass can find it.
A second guard runs at insert time: a unique index on (user_id, kg_id, md5(subject_text)). If two parallel jobs both miss the cosine search and try to insert the exact same string, one gets the existing ID back via ON CONFLICT. Three layers of dedup - semantic, exact-string, and the user lock - is the floor we needed to keep graphs clean.
The nightmares are the point
Here’s where it clicks. Every time the pipeline gets a merge wrong, that’s a nightmare - a subject conflict the system needs to resolve. And the system does resolve them, in two ways:
The acute nightmare: We shipped a bug where we were sorting by cosine distance but comparing against a similarity threshold. Backwards. The result? A single mega-node per user containing every subject they’d ever discussed. Every user’s knowledge graph collapsed into one giant blob. That was the worst nightmare we ever had. We caught it, rebuilt every user’s graph from scratch, and locked in the 0.75 threshold.
The everyday nightmares: Even with the threshold correct, merge conflicts happen constantly. “Q3 OKR review” lands on “Q3 Planning” and appends a new context. The description gets messier. The node accumulates fragments that don’t quite fit together. These small nightmares are exactly what triggers the refinement pass (Stage 6) to wake up and consolidate. Without the conflicts, the refinement pass would have nothing to do. The nightmares are the input. The dreams - clean, compound, well-named subjects - are the output.
Stage 5: linking
This is the boring stage, and that’s the point. Once we have a subject ID (either reused or freshly inserted) and a pair ID (the memory we’re processing), we insert one row into the junction table:
func (s *Service) linkSubject(ctx context.Context, subjectID, pairID pgtype.UUID,
userID, kgID string, stats *KGStats) {
stats.SubjectsAdded++
if err := s.postgres.LinkSubjectToPair(ctx, postgres.LinkSubjectToPairParams{
SubjectID: subjectID, PairID: pairID,
UserID: userID, KgID: kgID,
}); err != nil { /* log and return */ }
stats.LinksCreated++
}The SQL is INSERT INTO subject_memory_pair_links ... ON CONFLICT DO NOTHING. The job can be retried without thought.
There’s a small janitor pass that catches pairs marked as stored but with zero junction rows. It resets their flags and re-runs them. We’ve never seen it fire in production. We keep it because the day we delete it is the day it would have fired.
Stage 6: refinement, or why the graph gets sharper with use
After a few weeks, some subjects accumulate descriptions like:
Q3 OKRs draft v1 | Q3 board deck outline | Q3 eng offsite agenda | Q3 budget review with finance
Each pipe is a memory that merged into the same canonical “Q3 Planning” node. The information is there, but it’s no longer a description - it’s a junk drawer. Each of those merges was a small nightmare. Now the refinement pass wakes up and resolves them.

Every sync run, after the link stage, we query for subjects whose description contains the separator and batch them in groups of fifty. Fifteen workers in parallel call the LLM to synthesize a concise name and a rolling narrative summary.
The output replaces both the canonical name (yes, it can change here - it’s earned the right) and the description. We then re-embed the cleaned text so the next pair you save dedupes against the consolidated vector, not the fragmented one.
This is the part that closes the loop on the title. The nightmares - messy merges, fragmented descriptions, nodes that don’t quite make sense yet - are literally the input to the refinement pass. Without them, there’s nothing to consolidate. The graph doesn’t just grow. It dreams through its conflicts until they resolve into something cleaner. Like waking up and finding that the thing you couldn’t articulate yesterday now has a name.
There’s one more flag - is_key_subject - that flips to true the moment a subject has at least one linked pair. The UI uses it to filter out noise. It’s the difference between “you have 4,800 subjects” and “you have 800 subjects, and 4,000 noise candidates we never showed you.”
How retrieval uses the graph
The dreaming pipeline would be just plumbing if nobody read from it. The reader is the ranker.

When you ask Ditto a question, the Composite MLP v2 ranker pulls about fifty candidate memories from pgvector, then scores each one on seven signals. Three come straight from the junction table:
w_subj_freq- topic prevalence. Sum of link counts across the candidate’s subjects, normalized in the pool. If a candidate is linked to a heavily-discussed subject, it ranks higher when the query is vague.w_subj_sem- topic semantic match. Max cosine similarity between the query embedding and any of the candidate’s subject embeddings. This is the signal that lets a long memory with one important buried phrase still surface - because that phrase became a subject.w_neighbor_density- topic clustering. How many other candidates share at least one subject with this one. When eight of fifty candidates cluster around the same topic, that’s almost certainly what you’re asking about.
Those three signals were the single biggest contributor to the recall jump from v1 to v2 of the ranker. They’re the dividend the dreaming pipeline pays.
Numbers from production
A few honest numbers from real users:
- 1 to 5 subjects per memory pair, with a median around 2.
- 0.75 cosine dedup threshold, top-5 candidates considered, first match wins.
- 30-second batch window in the queue. 15-minute timeout per job.
- 30 pairs per KG storage batch, fetched in rounds of up to 300.
- 5 concurrent LLM calls during extraction. 15 concurrent during refinement.
- One user’s top subjects today have 641, 370, and 143 linked pairs. Power users build dense graphs fast.
- A typical sync job after a chat session completes in 2 to 6 seconds end to end.
What dreaming gives up
The bipartite shape is a constraint, and constraints are interesting because of what they cost.
- No directed semantic relations. The graph can’t tell you “TypeScript” is a kind of “Programming Language” - it only knows you’ve discussed both, sometimes together. Ontology lives in the LLM, not in the schema.
- No edge weights at write time. Strength is computed at query time. Simple schema, meaning can evolve.
- Co-occurrence is the only relationship. Two subjects that should be related but never co-occurred are invisible to the graph. The refinement pass softens this by merging near-duplicates, but it doesn’t invent connections you never made.
These are deliberate trades. The graph Ditto builds is the graph your conversations describe, not the graph an LLM thinks you should have.
Why we call it dreaming
The first version of this pipeline ran inline during chat save. It was slow, it blocked the response, and worst of all, it made retrieval suspiciously good only for the messages you’d just sent - because the rest of your history hadn’t been re-evaluated yet.
The fix was moving it off the hot path. Async. Quiet. A consolidation that happens between conversations, where loose ends from earlier in the day get tied to threads they belong on.
The neuroscience parallel isn’t accidental. Your hippocampus replays and consolidates during sleep. Ditto’s dreaming pipeline replays and consolidates between your conversations. Neither process requires your attention. Both make the next retrieval better because of it.
We called it dreaming because that’s what it felt like. The code calls it RunFullSync. The human word is the right one.
Where to dig next
-
The full ranker that reads this graph: Doubling Memory Recall by Extending Ditto’s Ranker
-
The v1 retrieval design that started it: Learned Retrieval Weights
-
The UI on top of the graph: Your Personal Knowledge Graph
-
Omar
Open a thread.
Ditto remembers what matters from every conversation, so your next idea starts where your last one left off.