engineering
Teaching Memory to Find Itself
How Ditto's Seed Memories v4 finds the right memory from a vague question: a per-user query adapter and a subject graph that together lift Recall@1 by 7.6 points, train on CPU in seconds, and stay under a megabyte per user.
On this page
Teaching Memory to Find Itself
When you ask Ditto something indirect, like “what did I decide about that thing a while back?”, it has to find one specific memory out of thousands. There’s no keyword to match on, no obvious filter. Just a fuzzy question and a haystack of everything you’ve ever told it.
Ditto already does this with a strong, frozen text encoder (text-embedding-005, 768 dimensions) and cosine similarity: embed the question, embed every memory, rank by closeness. That baseline is good. The research question for Seed Memories v4 was narrower and more interesting: can a small, cheap, per-user model make it meaningfully better, without retraining the encoder, without a GPU, without shipping anything heavy?
The answer is yes, and it comes from two ideas that stack. One reads your knowledge graph. One is a tiny model that’s yours and only yours. Here’s the whole system in one picture:
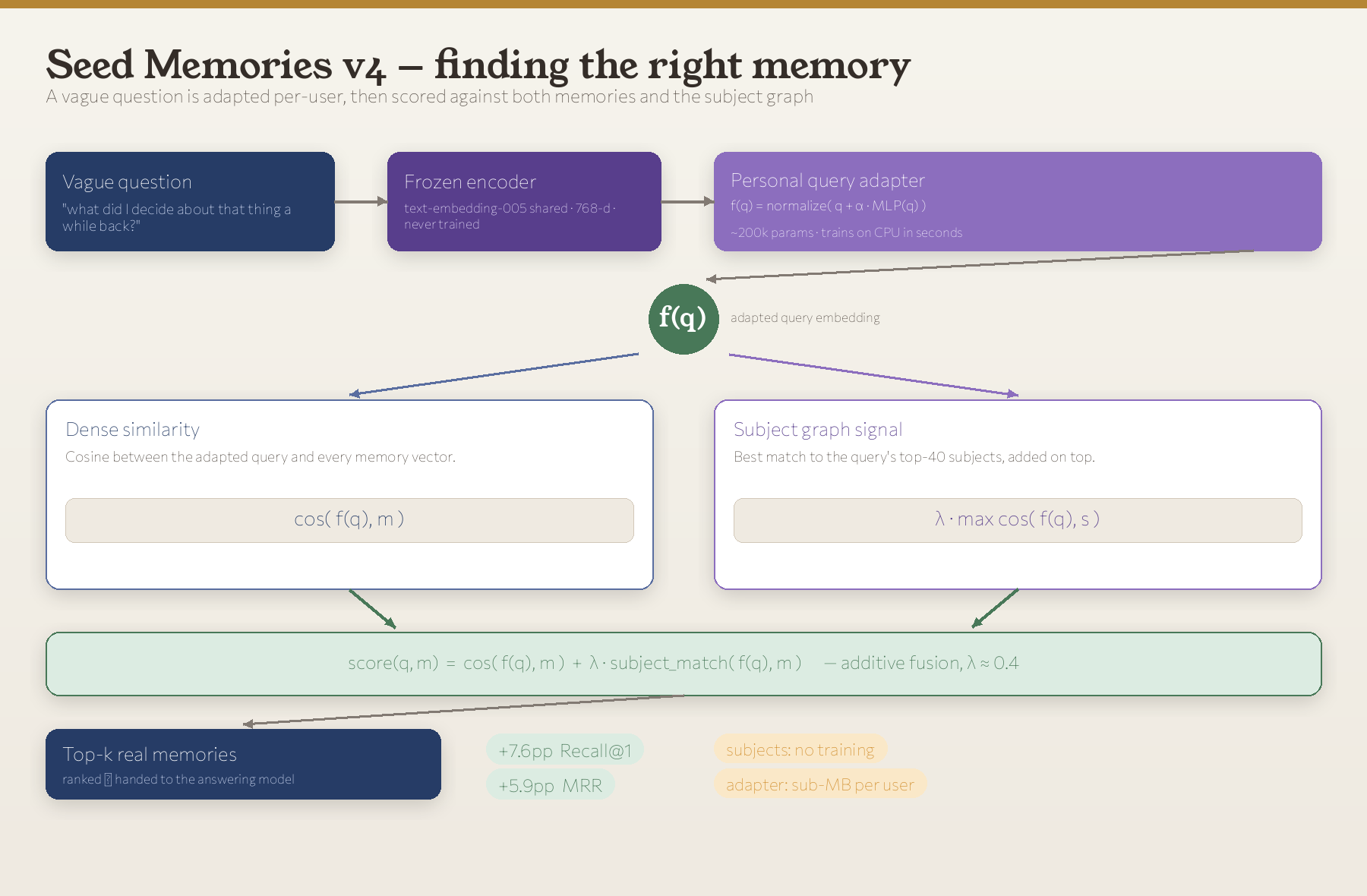
Everything to the left of the green f(q) node is shared and frozen. Everything to the right is cheap arithmetic over vectors you already have. The two scoring lanes, dense similarity and the subject graph, get added together, never multiplied, for a reason we’ll get to.
What we measured against
All the numbers below come from one real user’s memory store: about 2,200 real memories and roughly 200 held-out “hard” questions, the indirect, vague kind, with the answering memory known but deliberately hidden from the ranker. The metrics are the standard retrieval four:
- Recall@1: was the single right memory the very top result?
- Recall@5 / Recall@10: did it land anywhere in the top 5 / top 10?
- MRR: how high up was the first correct hit? (Position 1 scores 1.0, position 2 scores 0.5, and so on.)
- pp is a percentage point: 0.606 → 0.682 is +7.6 pp.
The dense baseline scores 0.606 Recall@1 and 0.705 MRR. That’s the bar to clear.
What works, part 1: the subject graph
Every Ditto user already has a knowledge graph. As you talk, Ditto extracts subjects (typed topics, people, projects, preferences) and links each one to the memories it touches. (That’s the dreaming pipeline at work.) We’d already seen that matching a query to subjects, rather than only to raw memories, was a powerful signal. v4 leans on it directly.
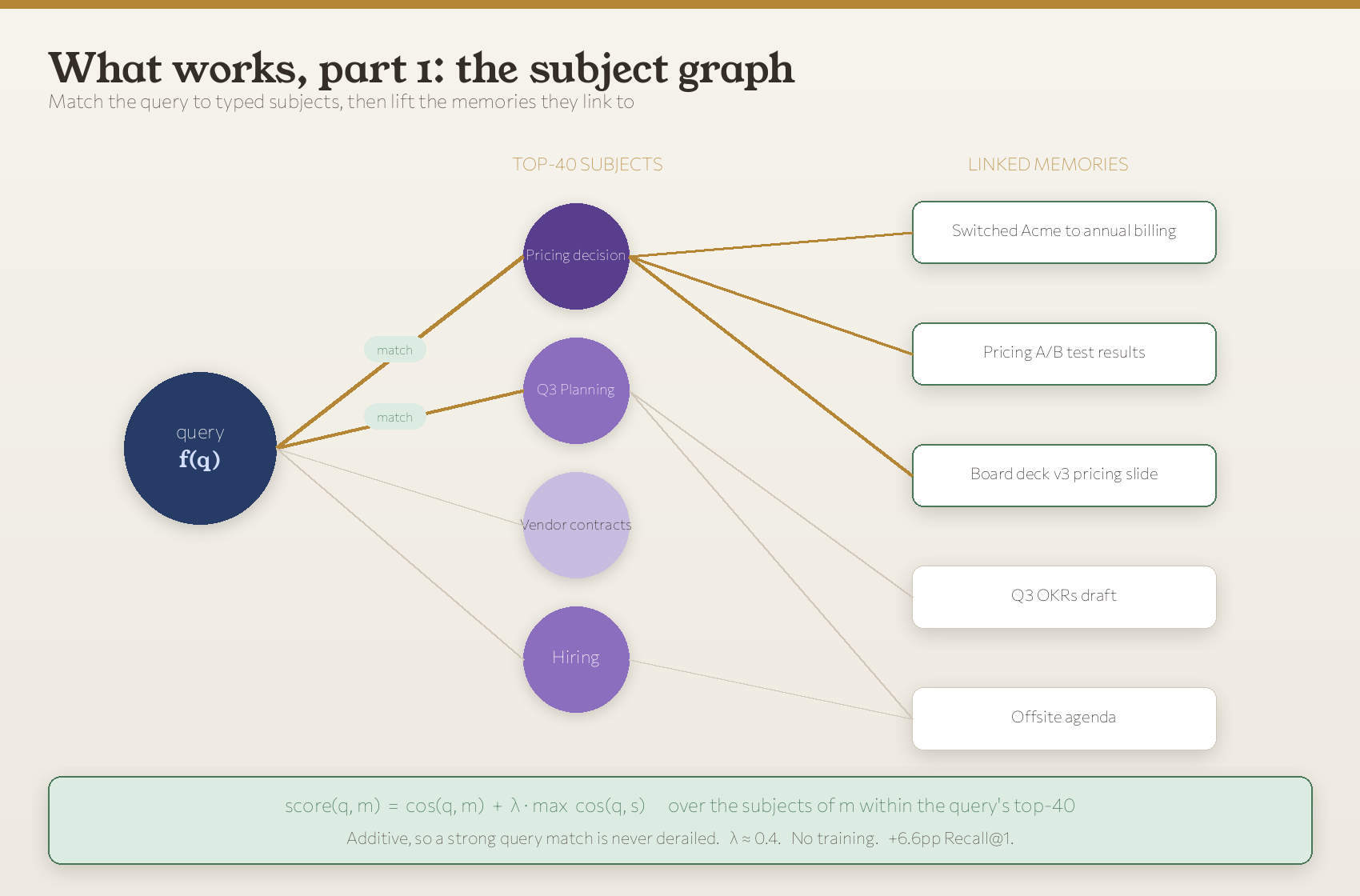
Instead of generating anything, we match the query to its closest subjects and then lift the memories those subjects link to. The fused score is:
Three design choices matter here:
- It’s additive, not multiplicative. A memory only gets a subject boost on top of its own dense score. A strong, direct query match is never derailed by the subject signal: subjects can only ever help a memory that already looks relevant. Multiplying would let a weak match be rescued (or a strong one be tanked) by graph noise; adding can’t.
- Fixed subjects can’t fabricate. The subjects are real entries in your graph. There’s nothing to hallucinate: the signal is grounded in topics you actually have.
- It’s free of training. Subject vectors live in the same 768-d space as memories. We embed them once. Scoring is a max and an add.
With λ ≈ 0.4 over the query’s top-40 subjects, subject fusion alone delivers +6.6 pp Recall@1 (0.606 → 0.672) and +4.5 pp MRR. No model, no fitting, no per-user state beyond the graph you already have.
What works, part 2: a tiny per-user adapter
Subject fusion improves the scoring. The second idea improves the query itself, and this is where each user gets their own model.
It is not a language model and not a fine-tune of the encoder. It’s a small residual MLP that nudges a query embedding toward the region of space where that user’s memories live, following Google’s “Search-Adaptor” recipe. The base encoder stays frozen and shared; only this little adapter is personal.
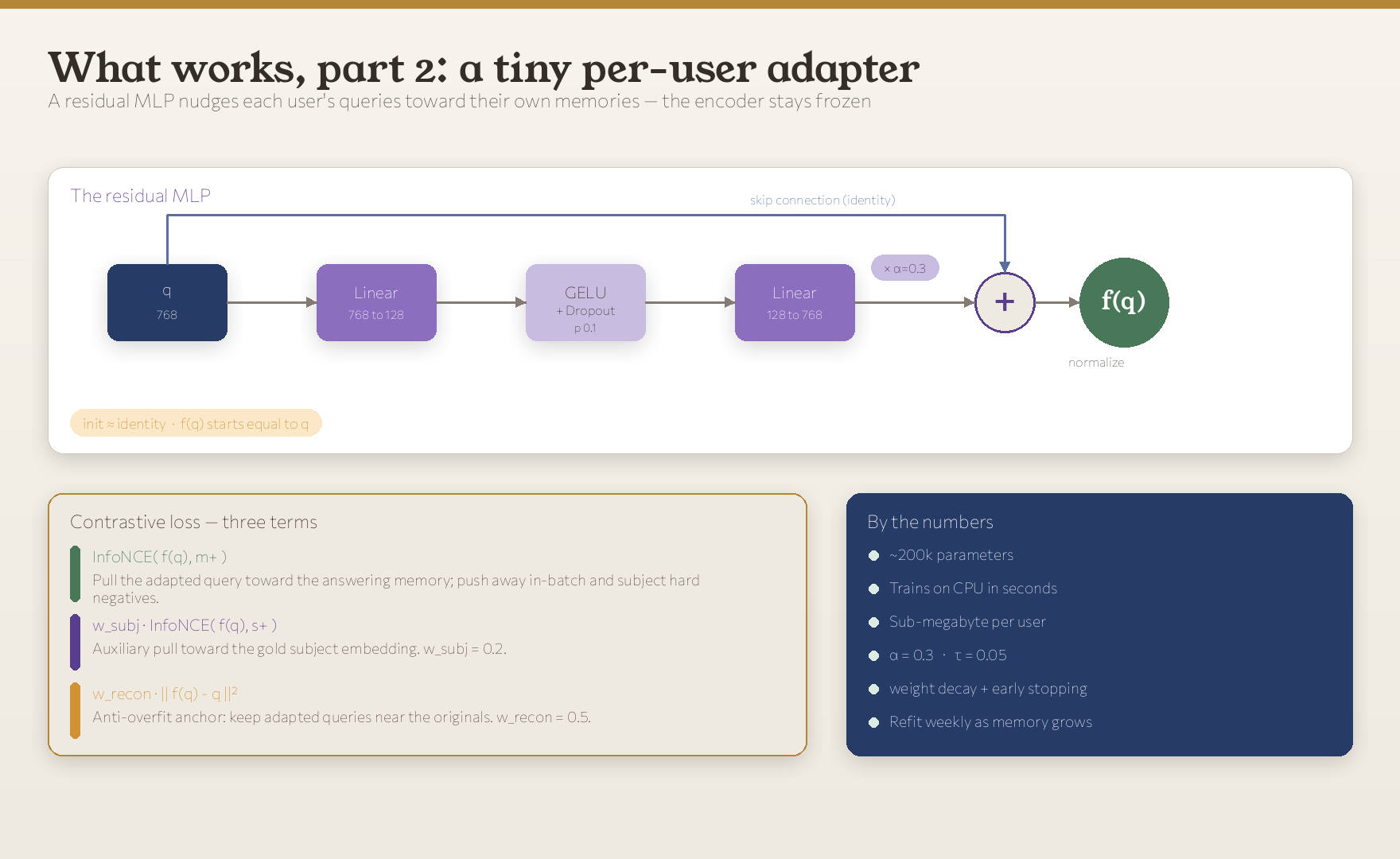
The adapter is a residual shift:
It’s initialized so the second linear layer starts at zero, meaning f(q) begins exactly equal to q, and training only ever moves it as far as the data justifies. With α = 0.3 and a 128-dim bottleneck, the whole thing is about 200,000 parameters: it trains on a CPU in seconds and saves to under a megabyte.
It learns from your own (query → answering memory) pairs with a three-part contrastive loss:
where InfoNCE is the standard contrastive term:
The first term pulls the adapted query toward the memory that answered it and pushes it away from everything else in the batch. The second is a gentle auxiliary pull toward the right subject (w_subj = 0.2). The third, the reconstruction anchor (w_recon = 0.5, τ = 0.05), is the one that makes this safe on small, personal data: it penalizes f(q) for wandering away from q, so a few thousand pairs reshape the geometry without distorting it. Our first attempts without that anchor actually made recall worse; adding the bottleneck, dropout, weight decay, and early stopping turned it into a reliable, monotone gain.
Pair selection matters
The negatives the adapter trains against come from the subject graph: memories that share a subject with the gold answer but aren’t it, the genuinely confusable ones. The catch is that some of those “negatives” are really just other correct answers. So we drop any candidate that’s too close to the gold:
Anything within 5% of the gold similarity is almost certainly a true match in disguise, and training against it would teach the model exactly the wrong thing.
Stacking them: Seed Memories v4
The full system adapts the query, scores it densely, and adds the subject signal, all at once:
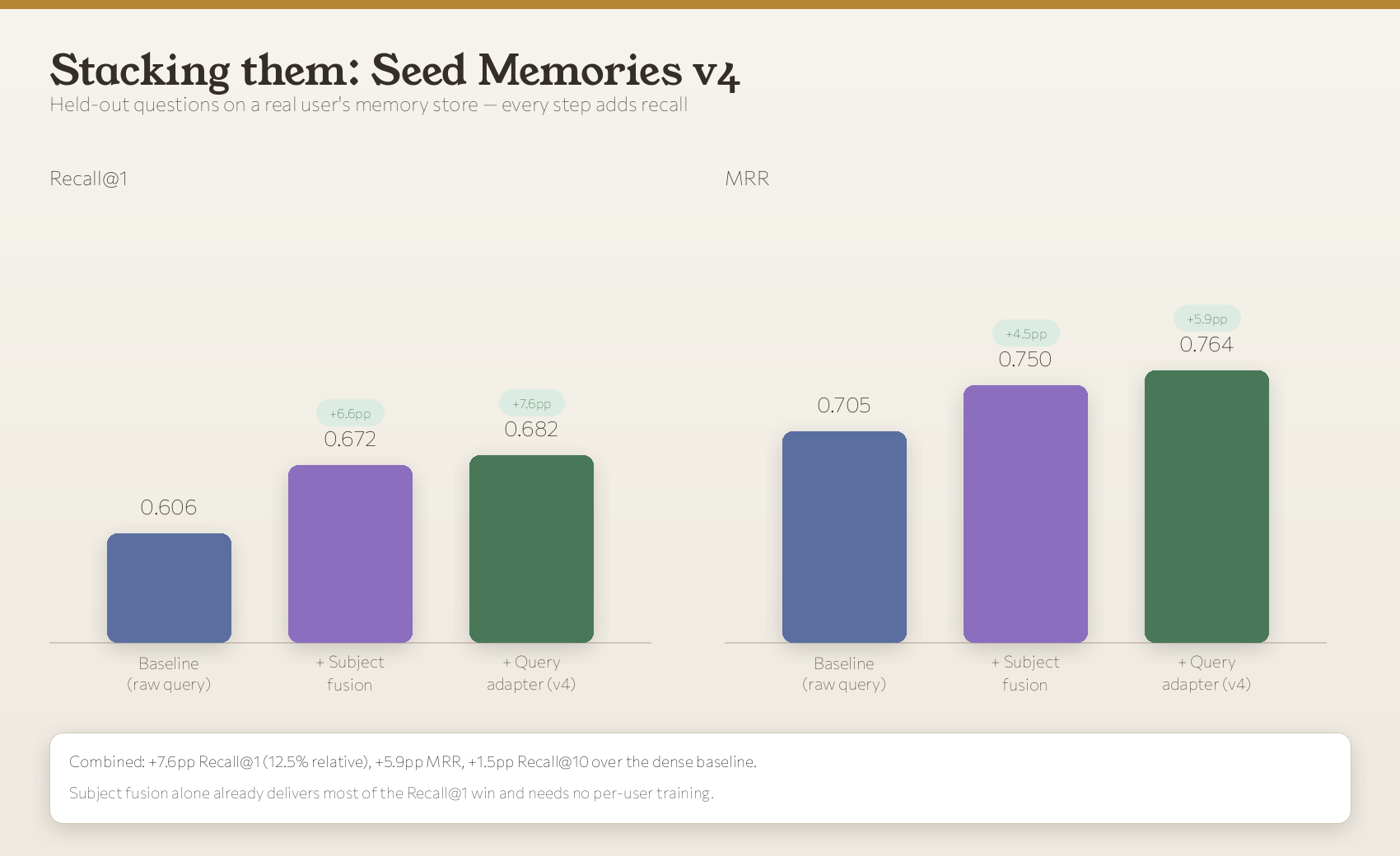
On the held-out questions:
| method | Recall@1 | Recall@5 | Recall@10 | MRR |
|---|---|---|---|---|
| baseline (raw query) | 0.606 | 0.818 | 0.894 | 0.705 |
| + subject fusion | 0.672 | 0.859 | 0.889 | 0.750 |
| + subject fusion & query adapter | 0.682 | 0.848 | 0.909 | 0.764 |
The combined system lands +7.6 pp Recall@1 (a 12.5% relative jump), +5.9 pp MRR, and +1.5 pp Recall@10 over the dense baseline. Notice that subject fusion alone already captures most of the Recall@1 win, which is exactly what you want, because it’s the half that needs no per-user training at all.
A negative we’re glad we checked
Before settling, we tried the obvious “smarter graph” idea: Personalized PageRank over the subject↔memory graph, the technique behind HippoRAG’s strong multi-hop numbers. On our task it was clearly worse: Recall@1 fell from 0.68 to roughly 0.42–0.54.
The reason is instructive. PageRank shines when answering a question means traversing several entities across multiple hops. Finding one memory is a single hop, and PageRank’s probability diffusion floods well-connected “hub” memories, burying the precise target. HippoRAG’s real engine isn’t the diffusion, it’s the query-to-entity linking, which is exactly what our subject fusion already does. We kept the part that works and dropped the part that doesn’t.
Shipping it for everyone
None of this is expensive to run for real users, because nothing heavy is per-user:
- The encoder is shared and frozen: one model for everyone.
- Each user gets a small subject-vector index (which the knowledge graph already maintains) and a sub-megabyte adapter.
- New users start with subject fusion alone. It needs no training and works from the very first memory.
- Once a user has accumulated enough
(query → memory)supervision to train without overfitting, they get a personal adapter, refit on a schedule (think weekly) as their memory grows, and a new adapter only ships if it beats the old one on held-out validation. No silent regressions.
That’s Seed Memories v4: a frozen shared encoder, a graph signal that’s free, and a personal model that costs one tiny MLP. Better recall on vague questions, and the worst case is “no worse than today.”
Coming soon: Generative Memories
There’s a third idea we’re building, and it’s the one I’m most excited about.
Imagine a per-user model that doesn’t just shift your query, but recalls in your own words, generating a fuzzy draft of the memory you’re reaching for, in your phrasing, with your specifics, and using that to retrieve. It’s the natural endgame for personal memory: a model that knows you well enough to finish your sentence before you do.
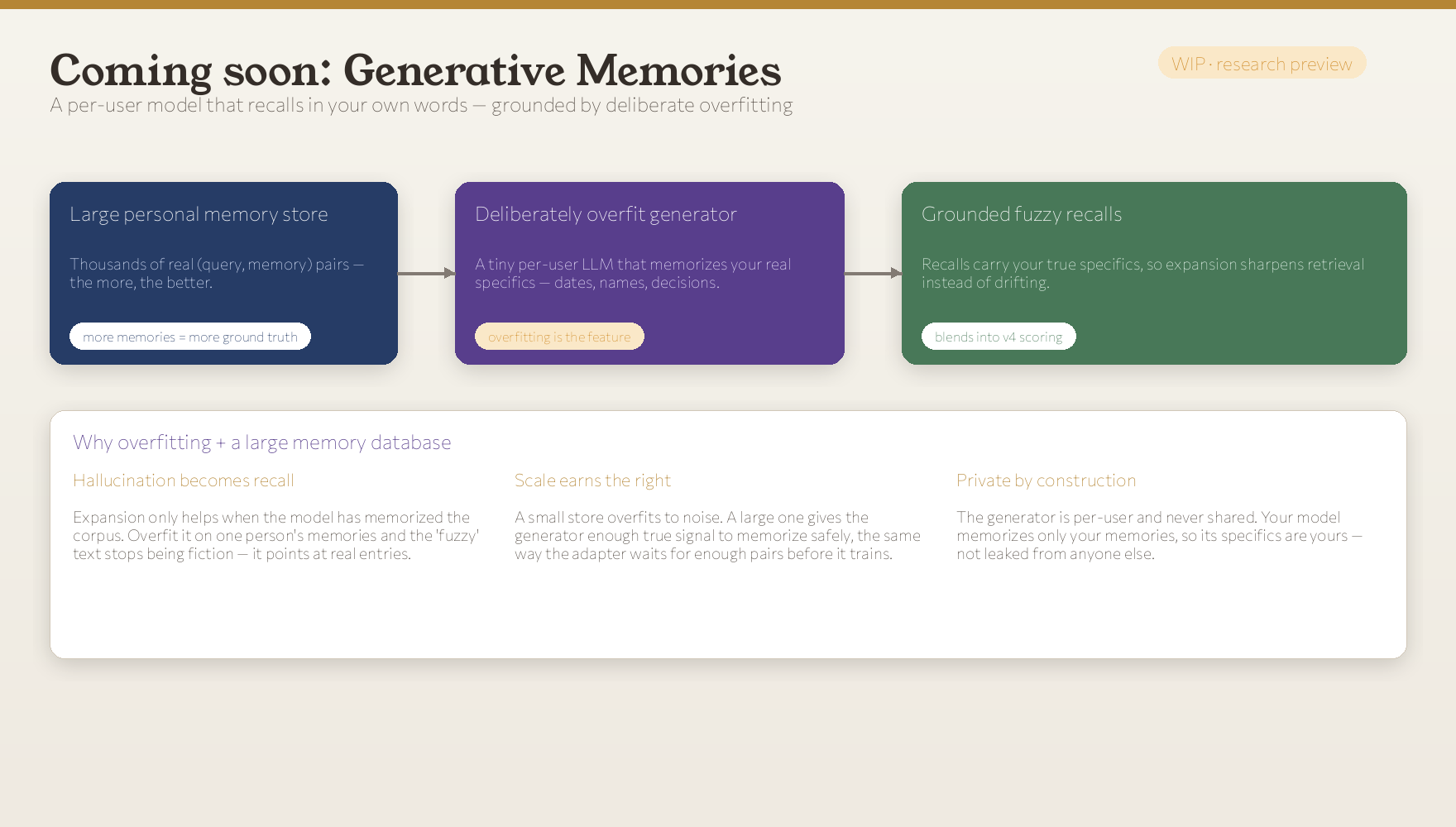
The whole game here is turning hallucination into recall, and it rests on two things that sound like sins and are actually the design:
Overfitting is the feature. A generic model asked to “imagine the memory” will produce the right theme with invented details: plausible dates, plausible names, none of them yours. That noise drifts the query away from the real entry. But a model deliberately overfit to one person’s memories stops inventing: when it generates a fuzzy recall, the specifics it reaches for are the ones it memorized, your real decisions, your real people. Expansion only helps a retriever when the model has memorized the corpus it’s expanding into. So we memorize it, on purpose, per user.
A large memory database earns the right to overfit. Overfit a tiny store and you memorize noise. Overfit a large one and you memorize signal: there’s enough true ground truth that the model can lock onto real entries instead of artifacts. This is the same gate the query adapter already respects: wait until there are enough pairs, then fit hard. The more you’ve trusted Ditto with, the sharper this gets, and because the model is per-user and never shared, the only specifics it can ever memorize are your own.
It’s still a work in progress: the engineering around training and serving a generative model per user is real, and we’re being careful about validating it the same way we validate everything else: it only ships if it wins on held-out questions. But the direction is set. Seed Memories v4 taught your queries to find the right memory. The next version will let your memory describe itself.
Omar
Sources
Seed Memories v4 builds on published work. In rough order of appearance:
- text-embedding-005. Google Cloud Vertex AI text embeddings, the frozen 768-dimensional encoder used throughout. Vertex AI text embeddings documentation.
- Search-Adaptor. Jinsung Yoon, Yanfei Chen, Sercan Ö. Arık, Tomas Pfister. Search-Adaptor: Embedding Customization for Information Retrieval. ACL 2024. arXiv:2310.08750. The frozen-encoder adapter recipe behind our per-user query adapter.
- InfoNCE / Contrastive Predictive Coding. Aäron van den Oord, Yazhe Li, Oriol Vinyals. Representation Learning with Contrastive Predictive Coding. 2018. arXiv:1807.03748. The contrastive loss the adapter trains on.
- GELU. Dan Hendrycks, Kevin Gimpel. Gaussian Error Linear Units (GELUs). 2016. arXiv:1606.08415. The adapter’s activation function.
- HyDE. Luyu Gao, Xueguang Ma, Jimmy Lin, Jamie Callan. Precise Zero-Shot Dense Retrieval without Relevance Labels. ACL 2023. arXiv:2212.10496. Generating a hypothetical document to retrieve with: the seed of the “recall in your own words” direction.
- Query2doc. Liang Wang, Nan Yang, Furu Wei. Query2doc: Query Expansion with Large Language Models. EMNLP 2023. arXiv:2303.07678. LLM query expansion for retrieval.
- HippoRAG. Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, Yu Su. HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. NeurIPS 2024. arXiv:2405.14831. Knowledge-graph retrieval with Personalized PageRank, the multi-hop method we tested and adapted.
- PageRank. Lawrence Page, Sergey Brin, Rajeev Motwani, Terry Winograd. The PageRank Citation Ranking: Bringing Order to the Web. Stanford InfoLab, 1999. Technical report. The personalized random-walk algorithm behind HippoRAG’s traversal.
Open a thread.
Ditto remembers what matters from every conversation, so your next idea starts where your last one left off.